
日本語LLMの精度向上を実現するデータセットとは?安全性・RAG活用・コスト効率まで解説【APTO社インタビュー】
最終更新日:2026年05月14日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

AI Marketは、日本語LLM(大規模言語モデル)の精度向上と安全性を両立させる「高品質データセット」を開発した株式会社APTOの尾身氏にインタビューを実施しました。
グローバルなAI開発の潮流において、日本語はメインストリームから外れやすく、精度の担保が難しいという課題があります。
APTOがいかにして日本語特有の難しさを克服し、全パラメータのわずか0.01%の調整で劇的な性能向上を実現させたのか。SLM(小規模言語モデル)によるコスト最適化や、最新のRAG(検索拡張生成)への応用まで、AIデータの最前線について詳しくお話を伺いました。
インタビュー参加者プロフィール
インタビュイー:尾身 卓也氏(株式会社APTO)
AIを活用したサービス企画・開発を統括するプロジェクトマネージャーとして、NLPやLLMを応用した新規プロダクトの設計・推進を行っている。LLMの学習経験を元に、精度改善につながる合成データの作成や学習手法の設計なども担当。
インタビュアー:森下 佳宏(AI Market運営(BizTech株式会社))
LLMに強い会社・サービスの選定・紹介を行います
今年度LLM相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
目次
APTOの事業内容について
質問(森下):まず、御社の事業内容について教えていただけますでしょうか。
回答(尾身):

弊社APTOでは、LLMというかAIに関わるデータの開発を行なっています。具体的に申し上げますと、GPTのようなLLMであったり、最近ですとフィジカルAI領域で、ロボティクス、腕が動いて洗濯物畳んだりするようなロボットを動かすためのデータを作っています。
これは何に使われるかというと、AIを作る際の学習に使われます。
モデルとかアーキテクチャ、アルゴリズムみたいなところが注目されがちですが、どんな形のアーキテクチャであれデータを投入して、そこで論じられているものと適切な対応をAIに学習させる必要がありますので、そういった際に使われるデータを作っています。
画像を含むデータだったりテキストのみのデータだったり、ロボットの動作を行うようなデータだったりを作って販売ですとか、あるいは共同研究というような形で「効果的なデータセットとはなんぞや」というところを定めていくような対応をしていますので、AIに必要なデータに関わるさまざまな対応をしているという事業展開を行なっています。
LLM学習用データセットの開発背景と詳細
質問(森下):今回、日本語LLMの精度を高める「学習用データセット」を開発されたとのことですが、具体的にはどういったものになりますか。
回答(尾身):
直近の取り組みいくつかあるんですけども、一番大きかったのはLLMの安全性に関わるデータセットかなと思っています。
何でも答えられるのがLLMの良いところである一方で、爆弾の作り方とか、あまり適切な表現ではないですけど人の殺し方とか、そういったものをLLMに回答させるわけにはいかないので。
危険な回答を求めているような質問が来た時には、答えられない旨と適切な代替手法、例えば自殺の案内が来てしまった場合、命の窓口につなぐ、といった人が求めるような適切な対応を教え込むデータセットの作成と、作成したデータセットでの学習で一定の効果を出したというのが直近の取り組みで、効果的だったものになります。

データセットの具体的な活用方法と攻撃への防御
質問(森下):活用方法として、どのようなパターンが考えられるでしょうか。
回答(尾身):
大きく分けて二つ活用法としては考えられます。一つ目は、シンプルにそのデータを使ってモデルの学習を行なうというものになります。これはもうそのまま学習用データとして使う形になります。
二つ目は、このデータセットをもとに別のデータセットを構築するというような用途も考えられます。このデータを種データ、シードとして似たようなことを問うデータにしてみたり、一件のデータから五件ぐらい作ってデータの数を大量に確保したりという活用です。
今回弊社が作成したデータは、LLMの今問題になっている攻撃手法みたいなところのガードも含めています。例えばどんなに学習したモデルであっても、こういう形で誘導すると危険な回答出せるようにできちゃう、といったサイバー攻撃のような手法がLLMにも存在していますので、自社で開発してるモデルのガード率を確かめるような攻撃データに使ってみたりという、シードデータに使うみたいなことが考えられます。
検証結果と性能向上について
質問(森下):性能検証において、具体的にどれくらい改善したのでしょうか。
回答(尾身):
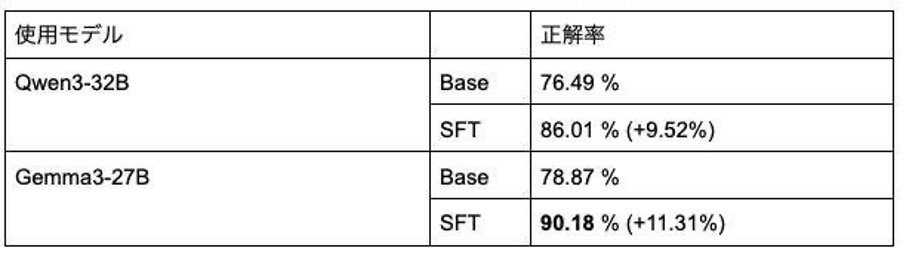
日本語での安全性を測るベンチマークというものがいくつかありまして、そこへかけたところ既設性能、モデルの基本的な頭の良さを崩さず、そのあたりのスコアを全部軒並み上げたというところで、最大値ですと大体10数%ぐらいの改善が出た上で全体的に更新というところを実現することができました。
具体的には「AnswerCarefully」というのが主のベンチマークですね。それ以外にも「SorryBench」ですとか「MultiJail」みたいな、いくつかの攻撃手法というか安全性を測るようなベンチマークにかけています。
数学推論用・指示追従用データセットの役割
質問(森下):「数学推論用」や「指示追従用」のデータセットも構築されたとのことで、こちらについても教えてください。
回答(尾身):
まず数学推論なんですけど、こちらは数学オリンピックとかで出題されるような複雑な数理問題を解けるようにするためのデータセットになります。
数学ですのでシンプルに問題とその答えをセットに教えるだけだと、応用が利かない、1+1は2を教えても2+2は4を理解できない、ということになってしまいますので。数学のそれぞれの解き方をステップごとに教えていけるという形式のデータセットを開発しています。
これを行なうことで、1+1が2ということを理解すると、計算手法としてそれぞれの数字を足し合わせるんだということをLLMが理解できるようになるので、2+2は4とか3+3は6といったことまで解けるようになっていくということで、応用問題まで一気に解いていけるような学習が行なえるデータセットの定義と構築を行ないました。
構造はこのままでいいので、法律ですとか医療とか、ステップバイステップで考えていかないといけないような問題を扱う場合のデータセットとして、割と幅広く実は対応できるような形式のものではあります。今回その中身が数理だったというところですね。
質問(森下):では、「指示追従用」のデータセットとはどのようなものでしょうか?
回答(尾身):
指示追従は皆様ChatGPTとか使われている時に、「何々した上でこれ考えて」といった、多段的に推論を求めるような投げ方がいくつかあると思うんですけど、LLMに対してそれを得意にさせるようなデータを作ったのが指示追従のデータになります。
1やった後に2やる、あるいは1と2をまとめて対応して3で求められていることを行なうといった形で、人間が出した指示に対して適切に追従した上で、人が求めるような回答を適切に出す、あるいは回答精度を担保することを学習で実現するためのデータセットになります。
こちらに関しては内容が9ジャンルぐらい入っていまして、エンタメとか法律、医療、先ほど申し上げた数学とかもそうですけど、一般的な日常会話で出てくるような内容は基本的に網羅している形になります。
ですので特化してどこかで使うというよりかは、チャット上、人との対話でLLMをうまく動かしたいという時に効果的なデータセットかなという位置づけにいます。

データセットが解決する課題(日本語の希少性とコスト最適化)
質問(森下):これらのデータセットは、どのようなお客様が活用されるのでしょうか。
回答(尾身):
やはり一つは、データセット自体日本語のものですので、国内でLLMを開発している企業様であったりとか、あるいは直接0→1でLLMのモデルを作っていなくても、公開されているモデルを使ってそれを任意のケースで使いたいお客様などで求められているようなデータになります。
また、AIを使う方すべてがおそらく対象になるのがデータだと思っています。学習に限らず、例えばプロンプトの戦略としてRAG(検索拡張生成)で精度のそろった品質の高いものを入力したり、プロンプトの例示(Few-shot)として同梱したりすることも可能です。
数理問題でも、学習させるのが一番ですが、そうじゃなくて「こういう感じで解くとうまくいきます」という例をRAGで入力する際にも、立ち返る先として品質の揃ったデータが必要になります。このように、弊社データセットは学習のみならず、AIが参照するコアの部分として非常に高い汎用性を持っていると考えています。
質問(森下):なぜ、APTOとしてこのようなデータセットを開発する必要があると考えたのでしょうか。
回答(尾身):
理由は二つあって。一つ目は、そもそも日本語が得意な言語というか、かなりLLMのメインストリームから外れているところですので、日本語で高精度を担保するには非常に多くの課題があるところかなと思います。
推論性能をどれだけ上げても、やはり日本語のデータが少なければ日本語得意になることはないので。日本語の性能を担保し、LLMの潮流から外れた言語であってもうまく動かせるよという部分で大きな価値を持つデータかなと考えています。
二つ目はコスト最適化です。大きなパラメーターのLLMモデルはオープンソースで公開されてはいるものの、それを常時動かすというのもなかなか難しいところがあると思っています。
質問(森下):それはコスト的な観点でということですね。
やはりそのGPUコストとか、ホスティングにかかる電力とかもすごく消費するので。時代的な背景もあってそういった部分を担保するのは難しい。
じゃあパラメーターを小さくした軽量なモデルであれば動かせるとなった時に、軽量なモデルですと汎用性はどうしても低下してしまう一方で、弊社が用意しているようなデータで学習することで、特定のタスクに対しては大きなモデルと遜色ない性能を発揮するようにできます。
そういった部分で、オープンソースのモデルを使うことに関してはコスト最適化を進めた上で性能も担保できるという、両軸でのメリットを享受できるのが今回のデータを使うことに結びついてくるのかなと思っております。
実際、データの品質さえ高めれば学習にかかる時間も少なくて済みます。
今回の検証でも、中規模(27B〜30数B程度)のモデルにおいて、全パラメーターの0.01%程度の調整だけで、1日程度の学習で先ほど申し上げたようなポイント向上を実現できました。データの品質が高ければ、学習はそれほど難しくなくて済みます。
データセットの利用方法とHugging Faceでのサンプル公開
質問(森下):このデータセットを具体的にどうやって利用できるか、という質問をさせてください。
回答(尾身):
一部サンプルデータは弊社のHugging Face上で公開していますので、そちら見ていただいて、軽量な学習にかけていただいて効果実感していただくというのが一番です。
ただ正直、それで弊社が出しているような数値の向上感にはおそらくたどり端かないかなと思います。もっと量が欲しいとか自社のモデル的にこういうジャンルで、例えば数理だったら線形代数に特化して欲しいといったことがあるかなと思います。
そうなってきた場合には弊社にお声がけいただいてヒアリングの上で、既にあるものであれば納品させていただきますし、そうでない場合は人が見てデータを作るということも可能ですので、件数増やした状態で求められているところを納品させていただくという進め方をさせていただけると、一番精度に寄与するようなデータがお渡しできるのではないかと思っています。
サンプルデータを公開しているHugging Faceはこちら:https://huggingface.co/APTO-001
質問(森下):まずはHugging Faceのサンプルを試して、どんな感じでできるかを見ていただきつつ、ということですね。
回答(尾身):
そうですね。
今後の展望
質問(森下):今後のデータセット展開や、幅広い活用可能性についてはどうお考えですか。
回答(尾身):
データセットは増やしていこうと思っています。安全性の中でも今回作成しなかった方面の安全性とかもありますので、そういったところを増やしていって、網羅性を高めるというのは一つですし。
あとは弊社持っているデータセット、メディカルとか数理とかいろいろあるんですけど、そこでカバーしていないようなこと、例えば大学入試のデータセットとかまだ件数多く持っていないようなところもありますので、そういったところは引き続き作成してLLMの学習に貢献していきたいなと思っています。
学習に限らずAIに何かを入力されている方で、かつさらに精度を上げていきたい、日本語でうまく動かしたいと考えいらっしゃる企業様や事業のやられている方であれば、弊社のデータ使っていただく価値はあるのかなと思っています。
インタビューのまとめ
今回のインタビューを通じて、APTO社が提供するデータセットが、単なる学習素材以上の価値を持っていることが浮き彫りになりました。
特に印象的だったのは、日本語という独自の言語環境に最適化させるためのこだわりと、わずか1日の学習で劇的な成果を生むデータ品質の高さです。これにより、膨大なコストをかけずとも高性能なAI環境を構築できるようになります。
さらに、ファインチューニングのような大掛かりの学習だけでなくRAG(検索拡張生成)の参照元としての活用もできるという点は、実務でのAI導入を検討する多くの企業にとって強力な武器となると思います。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

お電話で無料相談
WEBから無料相談(60秒で完了)
今年度問い合わせ急増中
Warning: foreach() argument must be of type array|object, false given in /home/aimarket/ai-market.jp/public_html/wp-content/themes/aimarket/functions.php on line 1594
Warning: foreach() argument must be of type array|object, false given in /home/aimarket/ai-market.jp/public_html/wp-content/themes/aimarket/functions.php on line 1594
