
MetaがSAM Audioを発表、テキストや視覚プロンプトで音声分離を実現
最終更新日:2025年12月19日

Metaは2025年12月16日、画像・動画のセグメンテーション技術SAMを音声領域に拡張したSAM Audioを発表した。テキスト、視覚、時間軸の3種類のプロンプトを組み合わせて複雑な音声から目的の音を分離できる初の統合モデルで、音楽、会話、一般音響の分離タスクで最先端の性能を達成し、リアルタイムより高速な処理を実現している。
- テキスト、視覚クリック、時間範囲指定の3つのプロンプト方式に対応した初の統合音声分離モデル
- 音声・映像エンコーダのPE-AVと拡散トランスフォーマーを組み合わせた生成モデリングフレームワークを採用
- 実環境での評価ベンチマークSAM Audio-Benchと自動評価モデルSAM Audio Judgeも同時公開
SAM Audioは、Metaが画像・動画のセグメンテーションで確立したSegment Anything Modelの技術を音声領域に適用した初の統合マルチモーダルモデルだ。
従来の音声分離ツールが単一用途に特化していたのに対し、SAM Audioは複数の入力方式を統合し、楽器分離、音声分離、一般音響分離といった多様なタスクで最先端の性能を実現している。
ユーザーはテキストで「犬の吠え声」や「歌声」と入力する方法、動画内で話している人物や楽器をクリックする視覚プロンプト、そして業界初となる時間範囲を指定するスパンプロンプトの3つの方法を単独または組み合わせて使用できる。これらのプロンプト方式は人間が自然に音声を認識する方法を反映しており、直感的な操作で高精度な音声分離を可能にする。
SAM Audioの技術的中核となるのは、フローマッチング拡散トランスフォーマーに基づく生成モデリングフレームワークだ。このアーキテクチャは音声ミックスと複数のプロンプトを受け取り、共有表現にエンコードした後、目的音声とその他の音声トラックを生成する。
モデルの学習には、高度な音声ミキシング、自動マルチモーダルプロンプト生成、堅牢な疑似ラベリングパイプラインを組み合わせたデータエンジンを開発し、実環境シナリオに対応する現実的な学習データを大規模に生成した。
学習データは音声、音楽、一般音響イベントを網羅する実音声と合成音声の混合で構成され、先進的な音声データ合成戦略により多様な環境での信頼性の高い性能を確保している。処理速度はリアルタイム係数約0.7と高速で、5億から30億パラメータの範囲で効率的にスケールする。

SAM Audioを支える技術エンジンがPerception Encoder Audiovisual(PE-AV)だ。PE-AVはMetaが2025年4月に公開したオープンソースモデルPerception Encoderを拡張し、コンピュータビジョンの先進機能を音声領域に適用している。
フレームレベルの動画特徴を抽出し、音声表現と時間的に整合させることで、視覚的に根拠のある音源(画面上の話者や楽器)を正確に分離し、シーンコンテキストから画面外の音声イベントも推論できる。
PE-AVは1億本以上の動画で大規模マルチモーダル対照学習を実施し、オープンデータセットと合成キャプショニングパイプラインのデータを活用して広範なカバレッジと高い汎化性能を確保している。
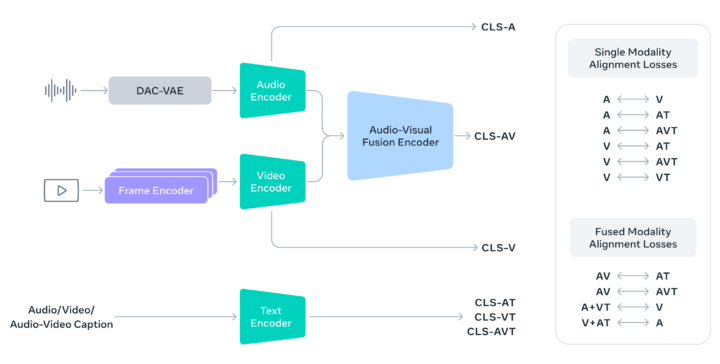
技術的にはPerception Encoderに加え、PyTorchVideoによる効率的動画処理、FAISSによる大規模セマンティック検索、対照学習フレームワークを統合し、テキスト、視覚、時間プロンプトに対応する柔軟で高性能なバックボーンを構築している。
Metaは評価基盤としてSAM Audio JudgeとSAM Audio-Benchも公開した。SAM Audio Judgeは人間の聴覚認識に近い方法で音声分離品質を評価する新しいフレームワークで、参照音声を必要としない客観的評価を提供する。
リコール、精度、忠実度、総合品質など9つの知覚次元を定義し、人間による5段階評価データを収集して学習している。SAM Audio-Benchは音声、音楽、一般音響効果の全主要ドメインをカバーする初の実環境音声分離ベンチマークで、高品質な音声・動画ソースから10秒サンプルを構築し、各サンプルに視覚マスク、時間マーカー、テキスト記述といった豊富なマルチモーダルプロンプトを付与している。
これにより参照トラックなしでの評価が可能になり、実際の使用環境により近い形でモデル性能を測定できる。SAM Audioは既存の最先端モデルを大幅に上回り、音声、音楽、一般音響の各カテゴリで専門特化モデルと同等の性能を達成している。
AI Marketの見解
SAM Audioは音声AI領域において技術的・実用的に重要な進展を示している。従来の音声分離技術が特定タスクに最適化された個別モデルの集合体であったのに対し、SAM Audioはマルチモーダルプロンプトによる統合アプローチを実現した点が画期的だ。
特に時間範囲指定によるスパンプロンプトは、ポッドキャスト収録中の犬の吠え声を一括除去するといった実用的ニーズに直接応える機能で、従来の音声編集ワークフローを大幅に効率化すると想定される。
技術面では、拡散トランスフォーマーと大規模マルチモーダル対照学習を組み合わせたアーキテクチャが、5億から30億パラメータでリアルタイムより高速な処理を実現している点は注目に値する。これはクラウドサービスだけでなくエッジデバイスでの展開可能性も示唆している。
参照元:Meta
SAM Audioに関するよくある質問まとめ
- SAM Audioはどのようなプロンプト方式に対応していますか?
SAM Audioは3種類のプロンプト方式に対応している。テキストプロンプトでは「犬の吠え声」や「歌声」といった記述で特定音を抽出でき、視覚プロンプトでは動画内の話者や楽器をクリックして音声を分離できる。また業界初のスパンプロンプトでは、目的音が発生する時間範囲を指定することで、ポッドキャスト全体から特定のノイズを一括除去するといった処理が可能だ。これらの方式は単独または組み合わせて使用できる。
- SAM AudioのベンチマークSAM Audio-Benchの特徴は何ですか?
SAM Audio-Benchは音声、音楽、一般音響効果の全主要ドメインをカバーする初の実環境音声分離ベンチマークだ。従来の合成音声や限定的な音源を使用するデータセットと異なり、高品質な実音声・動画ソースから10秒サンプルを構築し、視覚マスク、時間マーカー、テキスト記述といった豊富なマルチモーダルプロンプトを各サンプルに付与している。参照トラック不要の評価を実現し、実際の使用環境に近い形でモデル性能を測定できる点が特徴だ。

AI Market ニュース配信チームでは、AI Market がピックアップするAIや生成AIに関する業務提携、新技術発表など、編集部厳選のニュースコンテンツを配信しています。AIに関する最新の情報を収集したい方は、ぜひ𝕏(旧:Twitter)やYoutubeなど、他SNSアカウントもフォローしてください!
𝕏:@AIMarket_jp
Youtube:@aimarket_channel
TikTok:@aimarket_jp
過去のニュース一覧:ニュース一覧
ニュース記事について:ニュース記事制作方針
運営会社:BizTech株式会社
ニュース掲載に関するご意見・ご相談はこちら:ai-market-press@biz-t.jp

