
【AI論文解説】Evolving Deeper LLM Thinking:自然言語の答えを“遺伝子”として進化させ、より賢い解答を生み出す新しいアプローチ
最終更新日:2025年02月03日
記事監修者:吉井秀旭

高度化したLLM(大規模言語モデル)は、質問応答や要約など多様なタスクにおいて高いパフォーマンスを示しています。
しかし、解くべき問題が複雑で制約が多い場合、単純な出力生成だけでは精度が伸び悩むケースが増えています。
そこで、本論文では推論段階(推論時間)での計算資源をより活用し、モデル出力を改善する新たな枠組みとして進化的アルゴリズムを組み合わせた「Mind Evolution」を提案し、その有効性を示しています。
以下の解説では、提案手法の概要や実験的検証の結果、考察などを順を追って見ていきます。
- 論文名:Evolving Deeper LLM Thinking
- 論文著者:Kuang-Huei Lee, Ian Fischer, Yueh-Hua Wu, Dave Marwood, Shumeet Baluja, Dale Schuurmans, Xinyun Chen|Google DeepMind, UC San Diego, University of Alberta
- 論文提出日:2025年1月17日
- 論文URL:https://arxiv.org/abs/2501.09891
目次
本論文の概要
LLMが難易度の高いタスクに挑む場合、単純なサンプリングや逐次的な解答修正だけでは十分な性能が得られないことが指摘されています。
本論文では、その問題を解消すべく「Mind Evolution」という新たな進化的アルゴリズムを提案し、自然言語ベースの制約充足問題やステガノグラフィ的タスクに対しても高い効果を示しています。
提案手法は、単なるランダムサンプリングや逐次修正のような浅い探索にとどまらず、進化的アルゴリズムの概念を自然言語生成に応用しています。
具体的には、並行的に多数の解答候補を用意し、それぞれを選択・交叉・突然変異させるプロセスを世代交代ごとに繰り返すことで段階的に解答を洗練させ、それぞれの候補に対して評価器を用いて点数や違反事項をフィードバックし、最終的に最適解答に近づけることを目指します。
実験ではTravelPlannerやNatural Planなどの自然言語プランニングタスク、さらにStegPoetのような新規タスクにおいても顕著な性能向上が確認され、既存手法を上回る成功率を達成しました。
ポイント
- 単なるサンプリングや逐次修正ではなく、解答の「世代」を繰り返しながら探索するため、同じ回数・コストでも成功率が大きく向上
- 形式的な変数定義などを省き、制約も含めた自然言語の状態をそのまま遺伝子表現として扱えるため、複雑な問題設定や事前のフォーマル化が不要
- プログラム的に候補解答を採点・指摘する仕組みを組み込み、LLM側へテキストフィードバックを与えつつ、優秀な解答を選択・交叉・突然変異させることで、堅牢かつ高精度な探索を実現
Mind Evolution: 自然言語を「遺伝子表現」として扱う手法
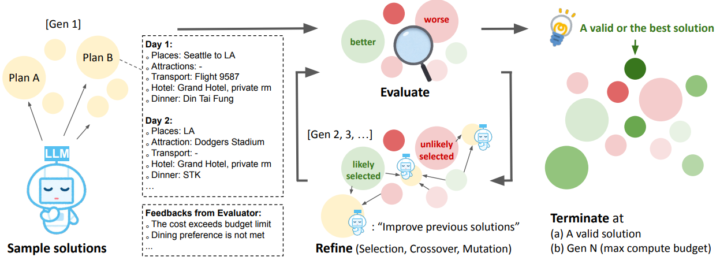
進化的アルゴリズムでは、通常はビット列や数値列といった形式的な「遺伝子情報」を用いて、世代交代のたびに交叉や突然変異を行います。
本手法では、その「遺伝子情報」となる部分を自然言語の解答文そのものに置き換えているのが特徴です。つまり、最適化の対象そのものがテキスト形式で記述された解答であり、その解答を進化的に更新していくというアプローチです。
Mind Evolution: 多数の解答候補の並行的な管理
Mind Evolutionでは、単に1つの解答候補を深く修正していくのではなく、複数の候補を同時に生成・評価・更新することで幅広い探索を行います。
具体的には、世代単位でそれぞれの候補を評価器にかけ、優秀なものを選び出して組み合わせたり、ランダムに要素を変化させる(交叉や突然変異)といった操作を繰り返すことで、多様な解答を並行的に進化させます。
こうした並行管理により、ある特定の問題点を抱えた候補だけに依存するリスクを避けながら、より良質な解答へと到達できる可能性が高まります。
Mind Evolution: Refinement through Critical Conversation(RCC)

並行して維持する各候補を修正する際に核となるのが、「Refinement through Critical Conversation(RCC)」と呼ばれる二役の会話フレームワークです。
RCCでは、まず現在の解答候補を批判的にチェックする「Critic」役が問題点を洗い出し、続いて修正版の解答を提案する「Author」役が改善案を出します。
評価器が「ここが予算オーバー」「この制約を満たしていない」といった具体的な問題点を挙げると、Criticがそれを参照して改善の方向性を指摘し、Authorが実際に修正した解答を生成するといった流れです。
例えば旅行プランニングのタスクでは、LLMが作った旅程に対して「この航空券を使うと到着時刻が不正」「予算を大幅に超過している」といった指摘を評価器から受け取ったうえで、Critic役とAuthor役が会話形式で改善策を練り、新しい旅程を再度生成します。このプロセスを複数回繰り返すことで、より良質な解答へと進化させます。
多様なタスクへの適用
著者らは本手法を、自然言語で表現される複雑な制約問題やステガノグラフィのようなタスクに適用し、その有効性を検証しました。
具体的には、旅行プランニング(TravelPlanner・Natural Plan: Trip Planning)や会議日程調整(Natural Plan: Meeting Planning)といった複数の制約を同時に満たす必要のある問題に加えて、隠しメッセージを創作文章に埋め込むStegPoetタスクにも適用しています。
評価器は各タスクの成否をプログラム的に判定し、それをフィードバックとしてやり取りすることで、従来の手法よりも高い正解率を得ることに成功しています。
実験結果
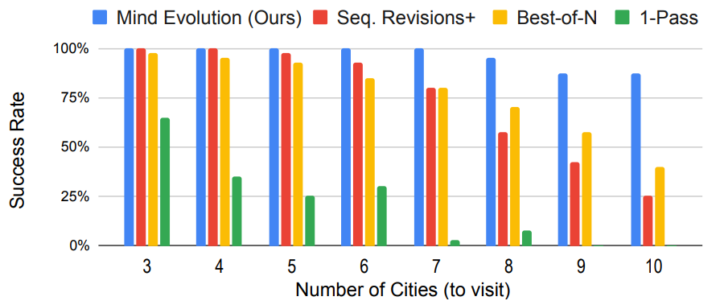
本論文の実験では、TravelPlannerやNatural Planの各種タスクを用いて、以下の3つのベースラインと比較が行われました。
その結果、Mind Evolutionは同じ生成回数(あるいは同じ程度のAPIコスト)に対して、より高い成功率や精度を達成しました。具体的には、TravelPlannerにおいては95%を超えるタスク成功率を示し、従来のBest-of-Nが約55%にとどまったのと対照的に、大幅な上昇を記録しています。
また、Natural PlanのTrip PlanningやMeeting Planningでも70〜80%台で頭打ちだったベースライン手法に対し、Mind Evolutionは90%台以上の成功率を実現しました。さらに、LLMそのものをより性能の高いモデル(Gemini 1.5 Proなど)に切り替える二段階方式を適用すると、ほぼ100%に近い解答成功率を示すケースもありました。
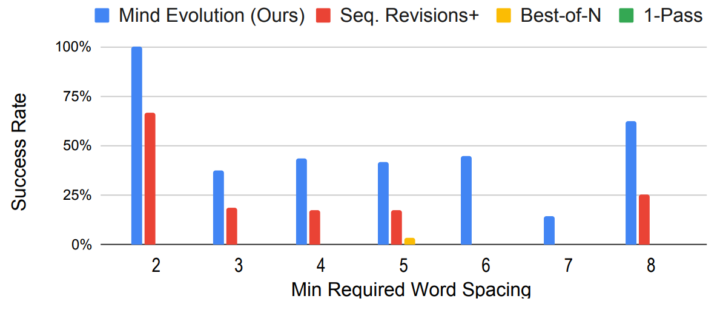
著者らはStegPoetという新タスクも導入し、指定された隠しメッセージを詩や物語に埋め込むステガノグラフィ的問題を検証しました。その結果でも、1-PassやBest-of-Nはほぼ解けなかった一方、Mind Evolutionは約45%超(さらに二段階方式で約80%超)まで達成し、進化的な探索手法の有効性を示しています。
考察と今後の課題
著者らは、本手法の成功要因として「自由度の高い自然言語表現を直接探索しつつ、評価関数からのフィードバックをテキストとして統合する能力」を挙げています。これは、難解な制約充足問題では問題の形式化がそもそも難しいため、進化的探索の強みが活かされる点だと考えられます。
また、解答の修正過程では部分的な手戻りや探索の拡散が起きやすいものの、島モデル(世代ごとに複数のサブ集団を進行させる手法)の導入によって解答の多様性が維持され、より良質な答えが生まれる可能性が高まっていると述べられています。
しかし、問題を評価する関数を事前に正しく設計する手間や、評価そのものが複雑になるタスクの場合への拡張など、多くの課題も残るとしています。
特に「評価器」を構築しにくいタスク(例えば完全に主観的な文章生成など)では本手法の適用は困難であり、今後は学習済みのAI評価モデルと組み合わせるなどの方向性も検討すると述べられています。
Agent-Rについてよくある質問まとめ
- なぜ従来の1-PassやBest-of-Nと比べて効果的なのか?
1-PassやBest-of-Nはランダムなサンプリングや単純な独立生成にとどまるため、問題をより深く理解して解答を改善する仕組みに乏しいからです。
Mind Evolutionでは、並行的に多様な候補を確保しつつ、CriticとAuthorが会話しながら解答を修正するため、より高品質な回答へ収束しやすくなります。
- “自然言語を遺伝子とする”とは?
進化的アルゴリズムではふつう、ビット列や数値列を遺伝子情報として扱い、それを交叉・突然変異して最適化します。
本手法では、その対象を「自然言語の解答文」そのものに置き換えています。解答文の一部を組み替えたり変更したりすることで、新たな候補解答を作り出す仕組みです。
まとめ
本論文は、LLMによる解答生成をより深く広く探索するための進化的アルゴリズム「Mind Evolution」を提案し、その大きな有効性を示しました。
TravelPlannerやNatural Planといった既存ベンチマークにおいて高い成功率を叩き出し、さらにStegPoetといった一筋縄ではいかない創造的タスクにも応用可能であることが示されています。
著者らは、自然言語のままの「解答」を直接組み合わせ・変異させる発想がさまざまな応用に波及する可能性を示唆し、フォーマルな定式化が困難な問題への新しいアプローチとして期待を集めています。
AI Marketでは、

東京大学工学部でAIについて学びながら研究を行った後、東京大学大学院に進学し研究を続けています。研究内容は、錯覚を伴う身体運動を、制御や最適化に基づくシミュレーションでモデル化することです。本アカウントでは、AI関連の最新論文などの解説を行っています!

