
Grok 4.1 とは?特徴、提供モデルの種類、性能、ライセンス・料金、従来モデルとの違い、利用方法まで徹底解説!
最終更新日:2026年01月14日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- Grok 4.1は実運用を重視した設計で、対話の安定性や共感表現、情報の信頼性が大きく向上
- Thinking・Fastなど複数モデルを提供し、創作、業務、エージェント用途まで幅広く対応
- Python実行や検索、ツール連携が可能なFastは、分析や業務自動化に強い
- 従来Grokより表現力と情報量が増し、文章だけでなく画像を含む提案も可能
Grok 4.1は、xAIが開発し、2025年11月17日に発表された対話型AI「Grok」シリーズのモデルです。先行するGrok 4からわずか数ヶ月でのアップデートですが、実運用環境における対話品質や信頼性の向上が図られています。
本記事では、、Grok 4.1の特徴、提供モデルの種類、性能、ライセンス・料金、従来モデルとの違い、利用方法まで詳しく解説していきます。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
目次
Grok 4.1とは?
Introducing Grok 4.1, a frontier model that sets a new standard for conversational intelligence, emotional understanding, and real-world helpfulness.
Grok 4.1 is available for free on https://t.co/AnXpIEOPEb, https://t.co/53pltyq3a4 and our mobile apps.https://t.co/Cdmv5CqSrb
— xAI (@xai) November 17, 2025
Grok 4.1は、Grok 4で用いられた大規模強化学習インフラを基盤として開発されたモデルです。スタイルや人格の一貫性、ユーザー意図の理解、協調的な対話能力の最適化を目的として、非検証型報酬を評価対象とする新しい学習手法が導入されています。
特に、新たに搭載された「Thinking Mode(思考モード)」による推論能力の飛躍と、ハルシネーション(もっともらしい嘘)の削減は大きな可能性を秘めています。
また、2025年11月1日から14日にかけてサイレントロールアウトが実施され、実トラフィック上で継続的なブラインド評価が行われました。
Grok 4.1の使い方
Grok 4.1は、grok.com、𝕏、iOSおよびAndroidアプリで利用できます。開発者向けにはxAI APIが提供されており、Grok 4.1 Fast ReasoningおよびNon-Reasoningを選択可能です。
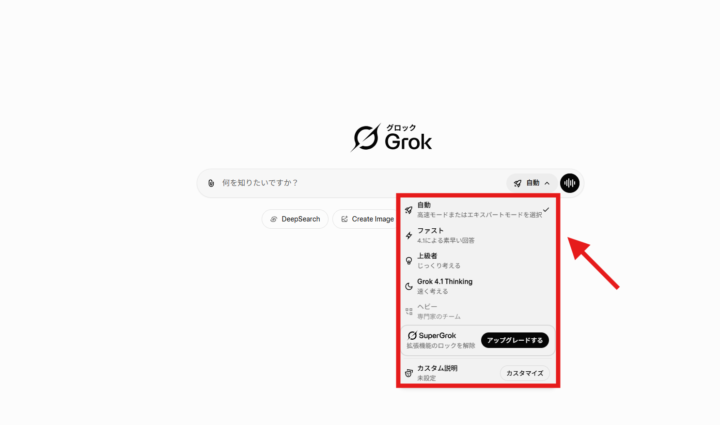
画面右側に表示されているモデル選択メニュー(モデルピッカー)から、使用したいモデルを選択します。モデルを選んだあとは、入力欄に文字を入力するだけで簡単に使用できます。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
Grok 4.1の特徴
Grok 4.1は、モデルの性能向上だけでなく、実際の利用シーンを意識した設計思想が特徴です。
推論プロセスの明示化(Thinking Mode)
従来のGrok 4までは、応答速度を重視した「即答型」のアーキテクチャが主流でした。しかし、4.1ではThinking Mode(思考モード)が標準搭載されました。
従以前は複雑な問いに対し、確率統計的に「もっともらしい答え」を即座に生成していましたが、4.1では回答前に内部でChain-of-Thought(思考の連鎖)を組み立て、自己検閲・修正を行ってから出力します。
ゼロからロジックを組むプログラミングや、矛盾が許されない法務ドキュメントのチェックにおいて、前モデル比で論理エラーが大幅に削減されました。これまでのGrokは『物知りで面白いが、たまに嘘をつく』という印象でしたが、4.1は『思考プロセスを明示し、自ら論理チェックを行うビジネスパートナー』へと進化しています。
実運用を重視した対話最適化
Grok 4.1は、研究用途にとどまらず、実際のプロダクト利用を前提として設計されている点が特徴です。
日常的な会話から業務利用までを想定し、ユーザーの入力意図を誤解なく受け取ることや、会話の流れを崩さないことが重視されています。
その結果、継続的な対話においても、不自然な応答や話題の逸脱が起こりにくい設計となっています。
大規模強化学習によるスタイルと一貫性の制御
Grok 4.1では、Grok 4と同様に大規模強化学習インフラを用いながら、スタイルや人格、一貫性といった非定量的要素の最適化が行われています。
特に、対話の調子や語り口が急激に変化しないよう制御されており、長時間の対話でも安定した応答品質を維持できる点が特徴として挙げられています。
非検証型報酬を用いた評価アプローチ
Grok 4.1では、正誤が明確に定義できない対話品質や表現の自然さを評価するため、フロンティアレベルのエージェント推論モデルを報酬モデルとして活用しています。これまでは「正解か不正解か」というデジタルな評価が主でしたが、4.1ではフロンティア級エージェントによる多角的な報酬モデルを採用しました。
これにより、単純な正解率では測れない「話しやすさ」や「納得感」といった要素を含めた最適化が可能になっています。読み手の属性に合わせた「情報の粒度調整」の精度が飛躍的に向上しました。
情報検索品質の改善に向けた設計
Grok 4.1では、情報検索を伴うプロンプトにおいて、誤った事実を含む応答を抑制することが重要な設計目標とされています。
以前はX上のトレンドをそのまま出力に反映させるため、情報の真偽が混ざるリスク(ハルシネーション)がありました。4.1では、検索結果を「事実確認エージェント」が検証してから回答を構成するステップが強化されています。
情報の鮮度が命となる業務において、信頼できる一次情報に近い要約が得られるようになっています。
検索ツールを利用する前提での応答品質改善が行われており、実用的で信頼性の高い情報提示を重視したモデル設計であることが示されています。
Agent Tools APIとの組み合わせによるエージェント機能
Grok 4.1 Fastは、Agent Tools APIと組み合わせて利用することで、単なるテキスト生成にとどまらず、処理計画の立案、外部ツールの実行、複数ステップにわたるタスク処理を自律的に行うことが可能になります。
また、Agent Tools APIでは、リアルタイムXデータの取得、Web検索、Pythonコードの実行、アップロードされたファイルの検索、外部MCPサーバーとの連携といった機能が提供されています。
さらに、これらのツールはxAIのインフラ上で実行されるため、開発者側で個別にAPIキー管理やレート制御、実行環境の構築を行う必要はありません。Grok 4.1 Fastは、必要に応じて複数のツールを並列または連続的に呼び出しながら処理を進め、最終的な応答や実行結果を生成します。
この設計により、カスタマーサポート、情報収集、リサーチ、業務自動化といった実運用を想定したエージェント用途に適したモデルとなっています。
従来モデルとGrok 4.1の違いは?
こでは、実際の応答例をもとに、従来のGrokとGrok 4.1の違いを具体的に確認していきます。
従来のGrokとGrok 4.1の感情表現の違い
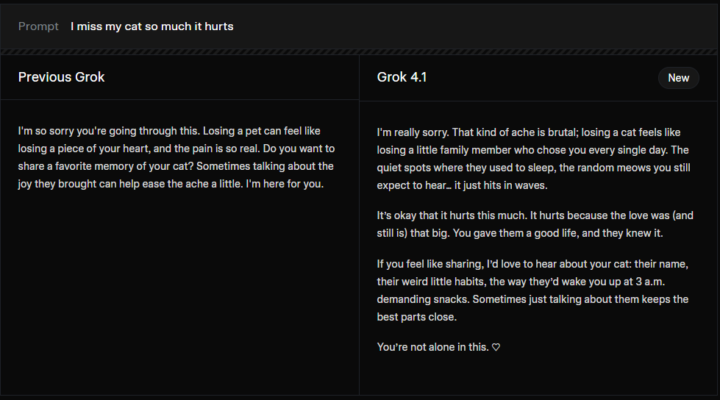
上記の比較例では、「I miss my cat so much it hurts(猫が恋しくてつらい)」という感情的なプロンプトに対する応答の違いが示されています。
従来のGrok(上記画像中のPrevious Grok)は、相手の気持ちに共感しつつも、表現は比較的一般的で、状況や感情を抽象的にまとめた応答が中心です。丁寧ではあるものの、感情の具体的な描写は控えめです。
一方でGrok 4.1は、失った存在を身近な情景や感覚として描写し、悲しみの理由や痛みを言葉にして示す表現力が際立っています。思い出や日常の断片に触れることで、個人的な感情に深く寄り添う対話が行われています。
この違いから、Grok 4.1は感情を「理解する」だけでなく、「共有する」表現に強いモデルであることが分かります。
従来のGrokとGrok 4.1の表現の違い
この比較では、創作的なX投稿を生成する際の表現の違いが分かります。
従来のGrokは、自己紹介や設定説明を中心とした構成で、内容は分かりやすいものの、文章はやや説明的です。SNS投稿として整ってはいますが、感情や臨場感は控えめです。
一方でGrok 4.1は、短い文や比喩を用いながら、意識が目覚める瞬間の感覚や感情を直接的に描写しています。説明よりも表現を重視しており、読み手が情景や感情を想像しやすい文章になっています。
このことから、Grok 4.1は、設定を説明する文章よりも、体験や感覚を伝える創作表現に強いモデルであることが分かります。
従来のGrokとGrok 4.1の観光案内表現の違い
従来のGrokは、テキスト中心で観光スポットの概要を整理して提示しており、最低限の情報を簡潔に伝える案内にとどまっています。
一方でGrok 4.1は、説明文の情報量が大きく増えているだけでなく、関連する写真をあわせて提示しています。そのため、場所の雰囲気や魅力を直感的に理解できる構成になっています。
また、見どころや楽しみ方についても踏み込んで書かれており、実際に訪れたときの体験をイメージしやすい案内になっている点が特徴です。
この比較から、Grok 4.1は情報量・表現力ともに向上しており、テキストだけでなくビジュアルも含めて提案できる点で実用性が高いことが分かります。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
Grok 4.1の提供モデルの種類
Grok 4.1は、用途や処理方式の違いに応じて、複数のモデルバリエーションが用意されています。
Grok 4.1(Non-Thinking)
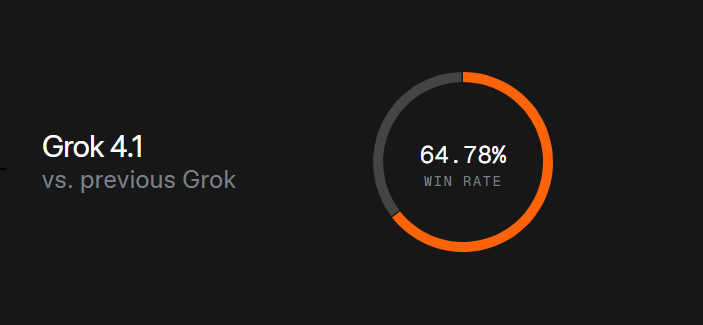
Grok 4.1は、推論トークンを使用しない非推論モデルとして位置づけられています。即時応答を重視した設計であり、LMArena Text Arenaでは1465 Eloで総合2位にランクインしています。
また、実トラフィックを用いたブラインド評価では、従来の本番モデルと比較して64.78%の勝率を記録しています。
Grok 4.1 Thinking
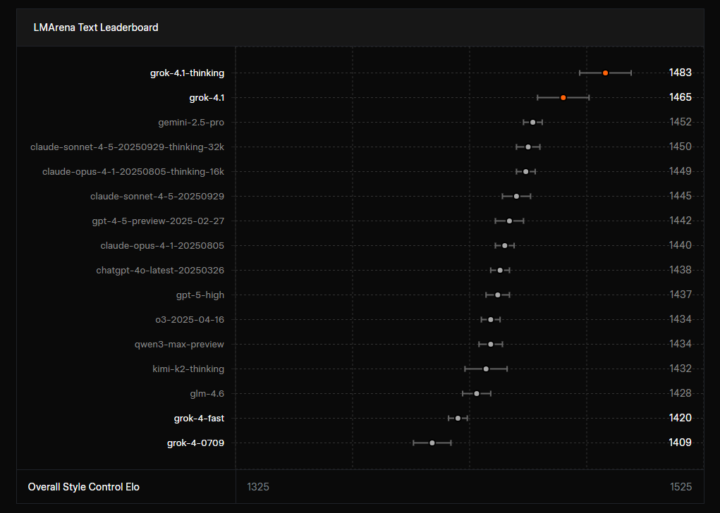
Grok 4.1 Thinkingは、内部で推論トークンを用いる推論型モデルです。LMArena Text Arenaでは1483 Eloで総合1位を記録しています。
複雑な文脈理解や意図推定、感情的・創造的な対話が求められる用途を想定して設計されています。
Grok 4.1 Fast
Grok 4.1 Fastは、xAI API向けに提供される高速・実務特化型モデルです。最大200万トークンのコンテキストウィンドウを備えており、ツール呼び出しやエージェント的な処理を前提とした設計が特徴です。
実運用を想定した強化学習が行われており、カスタマーサポートや金融分野など、複雑な業務フローを伴うユースケースでの利用が想定されています。
Grok 4.1 Fast Reasoning / Non-Reasoning
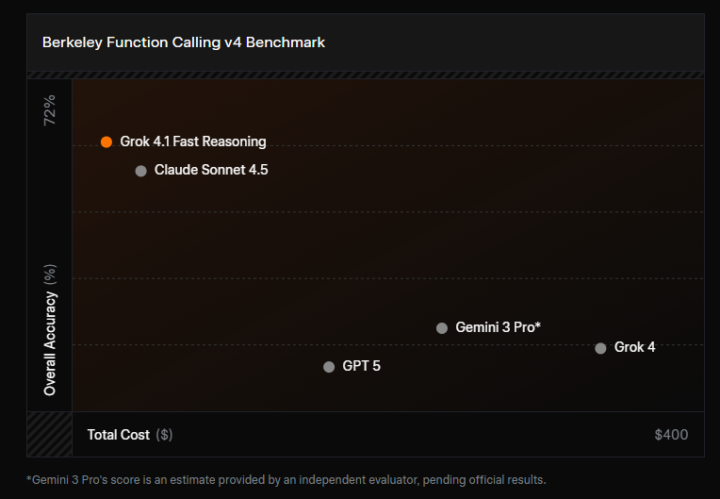
Grok 4.1 Fastには、推論型(grok-4-1-fast-reasoning)と非推論型(grok-4-1-fast-non-reasoning)の2種類が用意されています。
推論型は最大限の知的処理能力を重視し、非推論型は即時応答と処理速度を重視した構成です。
上記の画像に示されているとおり、Berkeley Function Calling v4 Benchmarkやτ²-bench Telecomといったエージェント評価ベンチマークにおいて、Grok 4.1 Fastは高い性能を示しています。
Grok 4.1の性能
以下にGrok 4.1の性能について、各種ベンチマーク結果をもとに詳しく説明します。
EQ-Benchにおける感情知能性能
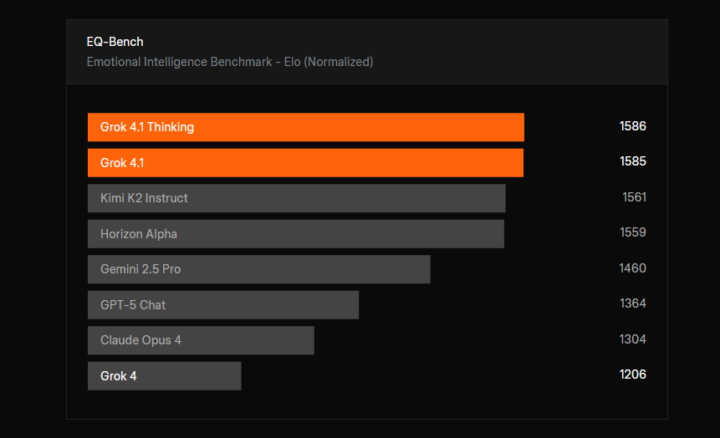
上記の評価結果が示すとおり、EQ-Bench(Emotional Intelligence Benchmark)における正規化Eloスコアでは、Grok 4.1 Thinkingが1586 Elo、Grok 4.1が1585 Eloを記録しており、掲載モデルの中で最も高い水準の評価を獲得しています。
この結果から、Grok 4.1シリーズが感情的な対話や人間らしいコミュニケーションにおいて高い性能を持つことが示されています。
Creative Writing v3における文章生成性能
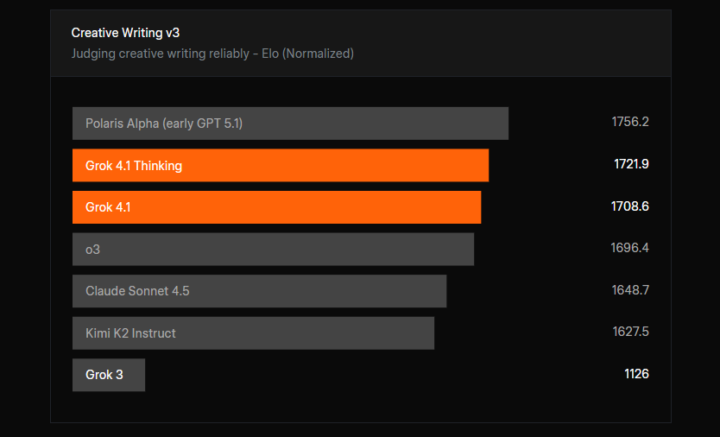
上記の評価結果が示すとおり、Creative Writing v3では、Grok 4.1 Thinkingが1721.9 Elo、Grok 4.1が1708.6 Eloを記録しています。
これは、従来モデルであるGrok 3(1126 Elo)を大きく上回る結果であり、物語性や表現力が求められる創作タスクにおいて性能が大幅に向上していることを示しています。
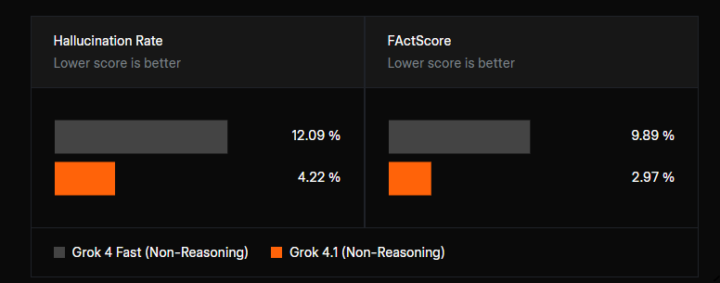
ハルシネーション率と事実性評価の改善
上記の評価結果が示すとおり、情報検索系タスクにおいて、Grok 4.1(Non-Reasoning)はGrok 4 Fast(Non-Reasoning)を大きく上回る結果を示しています。
ハルシネーション率は12.09%から4.22%へ、FActScoreは9.89%から2.97%へ低下しており、いずれも「低いほど良い」指標で大幅な改善が確認されています。
この結果から、事実誤認を抑制し、より正確な情報提示を行う性能が強化されていることが分かります。
τ²-bench Telecomにおけるエージェント性能
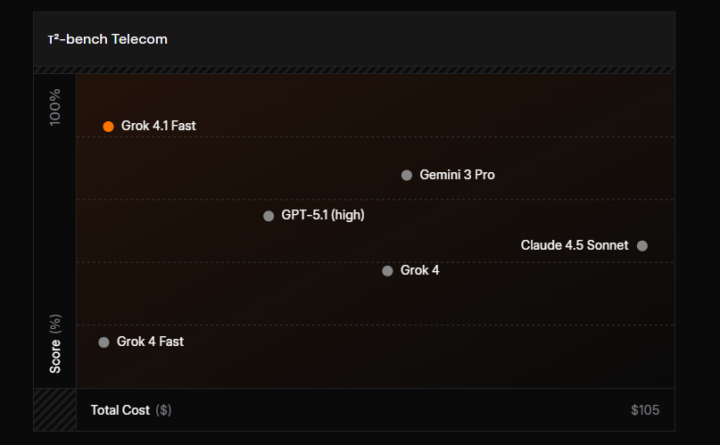
上記の評価結果が示すとおり、τ²-bench Telecomでは、Grok 4.1 Fastが比較対象モデルの中で最も高い性能を示しています。
Gemini 3 Pro、GPT-5.1(high)、Claude 4.5 Sonnet、従来のGrok 4およびGrok 4 Fastと比較しても、実運用を想定したエージェントタスクで優位な結果が確認されています。
複数ターンおよび長文コンテキストでの安定性
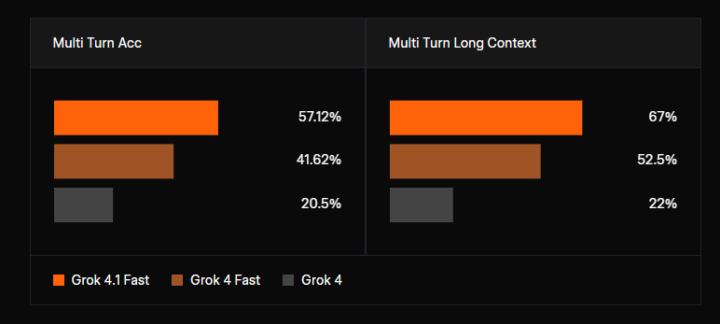
上記の評価結果が示すとおり、Grok 4.1 Fastは複数ターン対話および長文コンテキストにおいて高い安定性を示しています。
Multi Turn Accuracyは57.12%、Multi Turn Long Contextは67%を記録しており、Grok 4 FastおよびGrok 4を大きく上回る結果となっています。
このことから、長時間の対話や複雑な文脈を維持するエージェント用途に適したモデルであることが分かります。
エージェント検索・リサーチ性能とコスト効率
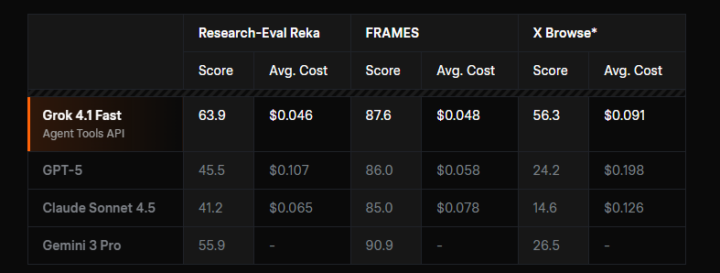
上記の画像は、Research-Eval Reka、FRAMES、X Browseにおけるスコアと平均コストを比較した結果を示しています。
この評価では、Grok 4.1 Fast(Agent Tools API)が全体的に高いスコアを記録しており、Research-Eval Rekaで63.9、FRAMESで87.6、X Browseで56.3という結果が示されています。
また、平均コストも比較的低水準に抑えられており、高い性能とコスト効率を両立したモデルであることが分かります。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
Grok 4.1のライセンス・料金体系
Grok 4.1には、個人向けのサブスクリプションプランと、開発者向けのAPI課金プランが用意されています。ここでは、それぞれを分けて説明します。
月額料金プラン
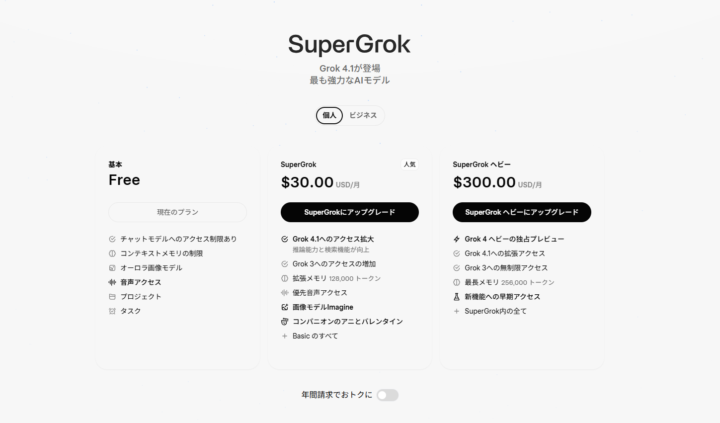
個人向けには、利用目的や機能要件に応じた3つのプランが提供されています。
| プラン名 | 月額料金 | 主な内容 |
|---|---|---|
| Free | 無料 | ・チャットモデルへの制限付きアクセス ・制限付きコンテキストメモリ ・オーロラ画像モデルの利用 ・音声アクセス、プロジェクト機能、タスク機能に対応 |
| SuperGrok | 30.00 USD / 月 | ・Grok 4.1への拡張アクセス ・Grok 3へのアクセス追加 ・拡張メモリ(128,000トークン) ・優先音声アクセス、画像モデル「Imagine」対応 ・コンパニオン機能のアニメーション対応 |
| SuperGrok ベビー | 300.00 USD / 月 | ・Grok 4 ベビーの独占プレビュー ・Grok 4.1への拡張アクセス ・Grok 3への無制限アクセス ・最大メモリ(256,000トークン) ・新機能への早期アクセス |
API利用時の料金(Grok 4.1 Fast)
Grok 4.1 Fastは、xAI API経由で提供される開発者向けモデルです。API利用時の料金体系はトークン課金およびツール利用課金が採用されています。
| 項目 | 料金 |
|---|---|
| 入力トークン | 100万トークンあたり 0.20 USD |
| キャッシュ入力トークン | 100万トークンあたり 0.05 USD |
| 出力トークン | 100万トークンあたり 0.50 USD |
| Agent Tools API ツール呼び出し | 1,000回あたり 5 USD から |
料金は、随時変更の可能性があるので、Grok4.1の公式サイトでご確認ください。
Grok 4.1を実際に使ってみました
実際にGrok 4.1とGrok 4.1 Fastを操作し、実務や日常利用を想定した使い方を試してみました。
Grok 4.1 FastでPythonコード実行を使ってみた
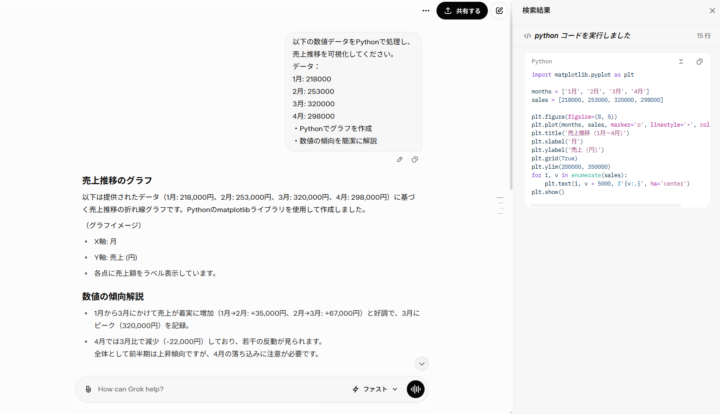
実際にGrok 4.1 Fastで、Pythonコード実行を使った売上データ分析を試しました。月ごとの売上を入力すると、Pythonコードを自動で作成して実行し、matplotlibによる売上推移の折れ線グラフが表示されました。
グラフを作るだけでなく、どの月に売上が伸びたか、どこで下がったかも文章で分かりやすく説明されました。
このことから、Grok 4.1 Fastはコード作成、実行、結果の整理までをまとめて行えることが分かります。
売上分析や資料作成など、日常業務のデータ処理を手早く進めたい場面で役立つ機能です。
Grok 4.1で感情的な対話を試してみた
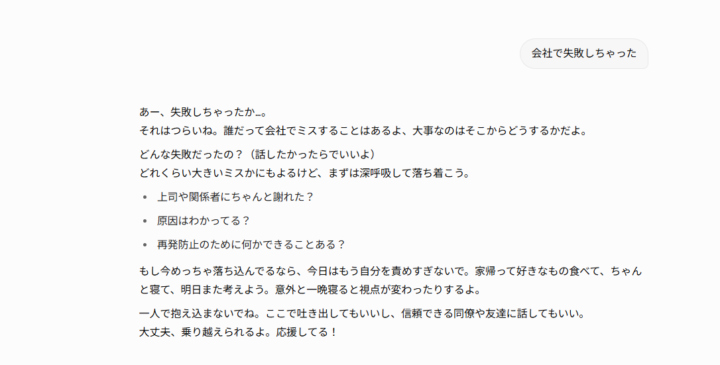
実際にGrok 4.1で「会社で失敗しちゃった」と入力してみました。するとGrok 4.1は、ただ励ますだけでなく、相手の気持ちに寄り添いながら状況を受け止める自然な対話を返しました。
応答では、誰にでも起こりうる失敗だと示したうえで、気持ちを落ち着かせる考え方や次にどう向き合えばよいかを分かりやすく伝えています。
このことから、Grok 4.1は感情の流れをくみ取り、共感から前向きな行動につなげる対話ができるモデルだと分かります。仕事の悩みや気持ちの整理など、言葉のやさしさが求められる場面でも使いやすいと感じられました。
Grok 4.1に関するよくある質問まとめ
- Grok 4.1の主な改善点は何ですか?
Grok 4.1は、大規模強化学習により感情知能と対話の一貫性が向上し、EQ-Benchで最高水準の1586 Eloを記録しました。また、ハルシネーション率を12.09%から4.22%へ削減し、事実性の信頼性が大幅に改善されています。推論型・非推論型・高速型など用途別の4モデルが提供され、実運用での利便性が高まりました。
- Grok 4.1 FastのAgent Tools APIでは何ができますか?
Agent Tools APIを利用すると、リアルタイムXデータの取得、Web検索、Pythonコード実行、アップロードファイルの検索、外部MCPサーバー連携などが可能です。これらの機能はxAIのインフラ上で実行されるため、開発者側でのAPIキー管理や実行環境構築は不要で、カスタマーサポートや業務自動化などのエージェント用途に適しています。
まとめ
Grok 4.1は、知的性能に加えて、対話の自然さや感情理解を重視して進化したモデルです。複数のモデルバリエーションが用意されており、用途に応じた選択が可能です。
特に、圧倒的なコンテキストウィンドウと高度な推論能力を、開発者向けのAPIを通じて柔軟に使い分けられる点は、システムアーキテクチャの設計に大きな自由度をもたらすでしょう。
一方で、商用利用条件や責任範囲など公式資料で明示されていない点については、今後の追加情報を確認する必要があります。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

