
Qwen3-VLとは?特徴、性能、モデルの種類とAPI料金、利用方法、実際の利用レポート、活用事例まで徹底解説!
最終更新日:2025年11月25日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- Qwen3-VLはAlibabaのQwenチームが開発したマルチモーダル基盤モデルでテキスト・画像・動画の理解と生成を統合
- Gemini 2.5 ProやGPT-5クラスと競合する性能
- ビジュアル・エージェント、空間理解と2D/3Dグラウンディング、長コンテキスト処理(最大1Mトークン)、多言語OCRを備え、知覚から推論・行動まで一貫して処理
- Plus/Flash/Instruct/Thinkingなど多様なモデルとAPI料金体系が用意
- クラウド経由の利用からローカル実行・ツール連携まで、研究開発から実務活用まで幅広いシーンで導入可能
Qwen3-VLは、AlibabaのQwenチームによって開発されたマルチモーダル基盤モデルでテキスト・画像・動画の理解と生成を高次元で統合したシリーズです。
従来のQwen-VLから大幅に進化し、視覚認識・空間理解・長文コンテキスト処理・マルチ画像対話・動画理解・エージェント操作まで幅広い領域をカバーします。
オープンソースのLLM(大規模言語モデル)として公開され、Gemini 2.5 ProやGPT-5といったクローズドモデルに匹敵する性能を、より少ない計算リソースで実現するとされています。
本記事では、Qwen3-VLの概要、特徴、性能、モデルの種類とAPI料金、利用方法、実際に利用した結果、活用事例までを詳細に解説します。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
目次
Qwen3-VLとは?

Qwen3-VLは、Alibabaが開発したQwenシリーズの中で高度な視覚言語モデルであり、テキストと言語の統合理解に特化したマルチモーダルAIです。AIが画像や映像を“見る”だけでなく、世界の構造や出来事を理解し、「理解・推論・行動」まで一貫して処理できるよう設計されています。
シリーズの中核である「Qwen3-VL-235B-A22B」はInstruct版とThinking版の2種類が公開されており、いずれもオープンソースとして利用可能です。
特に注目すべきは、その効率性と多機能性です。MoE(Mixture of Experts)構造を採用しており、大規模なクローズドモデルに匹敵する性能を、より少ない計算リソースで実現するように設計されています。
Instruct版はGemini 2.5 Proに匹敵、または上回る視覚認識性能を持ち、Thinking版はSTEM・数理推論など複雑なマルチモーダル課題で高い成果を示しています。
アーキテクチャを刷新
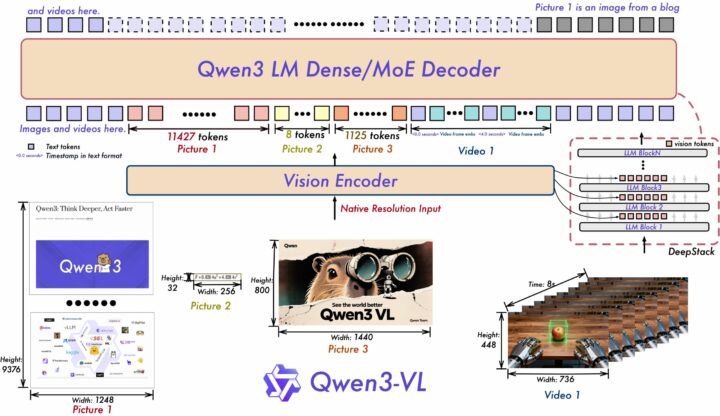
Qwen3-VLは動的解像度設計を維持しつつ、3つの要素を中心にアーキテクチャを刷新しています。
まず、Interleaved-MRoPEにより時間・高さ・幅の位置情報をインターリーブ形式で分散し、長時間動画の理解精度が向上しました。
さらに、DeepStack技術でViTの多層特徴を融合し、視覚トークンをLLMの複数層へ注入する方式に変更。これにより、低レベル〜高レベルの豊富な視覚情報を保ったまま処理でき、細部認識やテキスト画像整合が大幅に改善されています。
加えて、動画モデリングはテキストとタイムスタンプを整合させる新方式に刷新され、秒・HMS形式の時間出力にネイティブ対応。アクション境界検出やイベント位置特定など、時間推論タスクで精度が向上しました。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
Qwen3-VLの特徴
Qwen3-VLの特徴は以下の通りです。
ビジュアル・エージェント能力
Qwen3-VLは、画像を「理解」するだけでなく、人間のようにスマートフォンやPCを操作できるビジュアル・エージェント機能を備えています。
ボタン、入力欄など画面上のGUI(グラフィカルユーザーインターフェース)要素の認識や意味理解、入力フォームの自動処理などを通じて、アプリ起動や操作を自律的に実行することが可能です。また、ツール呼び出しを組み合わせることで、複雑なインターフェース操作や細部の知覚タスクにも対応しています。
AIがまるで人間のように、ブラウザ上のSaaSツールや社内システムを操作し、一連の業務プロセスを自動実行できる可能性を秘めています。
OS Worldなどの評価指標では世界トップ水準のスコアを記録し、視覚理解と実行制御を融合したインテリジェントオートメーションを実現しています。
空間理解と2D/3Dグラウンディング
Qwen3-VLは、画像や動画から方向・動作・移動パターンなどの空間的関係を読み取り、対象の位置関係や動きを正確に把握できます。また、絶対座標から相対座標への2Dグラウンディング転換や3Dグラウンディングに対応し、複数物体が存在する複雑なシーンでも高精度に検出ボックスを生成します。
さらに、3Dバウンディングボックスを用いて、対象の現実世界での位置・サイズ・奥行きを推定することができ、視点変化や遮蔽関係の理解精度も向上しています。
これにより、将来の動作計画や経路予測など、ロボティクスや自動運転、世界モデル分野の基盤技術として活用が可能です。
超長文脈と長尺動画の完全記憶と秒単位検索
すべてのモデルは256Kトークンを標準サポートし、最大1Mトークンまで拡張可能。2時間超の長尺動画でも秒単位で内容を参照できるため、長文・長動画の処理でも安定した精度を維持します。
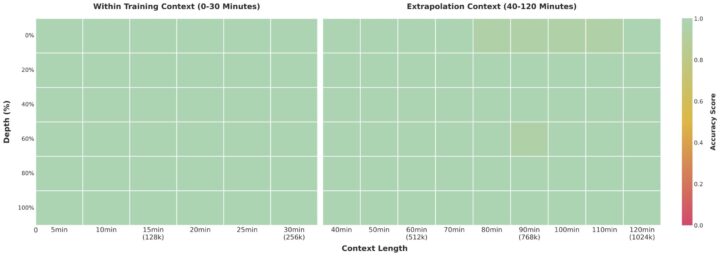
「needle-in-a-haystack」実験では256K入力で100%、1M入力でも99.5%の精度を維持し、長コンテキスト処理の信頼性が実証されました。
数百ページにおよぶ技術資料、契約書、または数時間に及ぶ会議録や監査映像を一度に入力し、文脈を見失わずに全体を理解できます。
32言語対応の多機能OCR
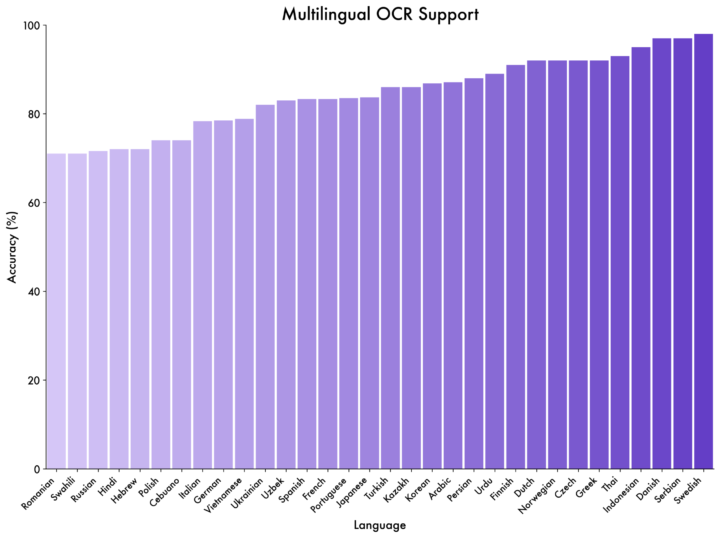
多言語OCRにおいては日本語を含む39言語のうち32言語で70%以上の精度を達成し、中国語・英語以外の言語にも広く対応しています。また、スキャン文書や表構造の解析、長文ドキュメントの理解にも適応しています。
実際にQwen3-VL-235B-A22Bを利用してみた

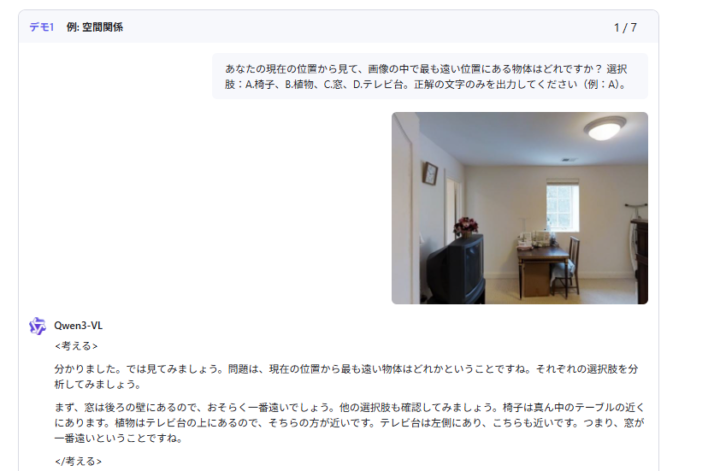
Qwen3-VL-235B-A22Bを使って、室内写真の中で「最も奥にある物体はどれか?」という空間理解テストを行いました。
モデルは2D画像から奥行き情報を正確に処理し、「手前(前景)」「中景」「背景」という概念を用いて、論理的に正解である「テレビ」を導き出しています。特に、「椅子はテレビの手前側」「机は最も手前」といったオブジェクト間の相対的な位置関係を言語化できている点は従来のマルチモーダルAIとは一線を画す能力です。
Qwen3-VLは単に「正解を当てる」だけでなく、どうしてその結論に至ったのかを視覚情報とテキスト推論を組み合わせて説明してくれるため、空間理解モデルとしての完成度がとても高いと感じます。単なる物体検出を超えた、高度な空間認識能力の実装が可能です。
この能力は倉庫内ロボットの自律移動における障害物回避判断や、リテール分野での棚割(プラノグラム)分析、あるいは監視カメラ映像における距離感を加味した異常検知など、物理世界とリンクした複雑なタスクにおいて高い信頼性と応用力を持つことを強く示唆しています。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
Qwen3-VLのベンチマーク傾向
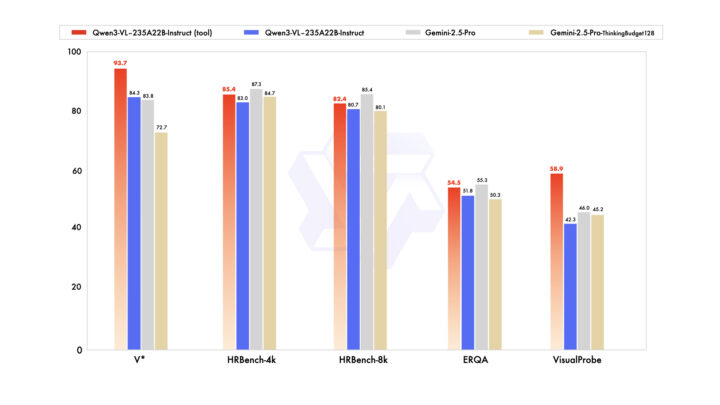
Qwen3-VLはマルチモーダル領域で高い処理性能を発揮します。
Instruct版は大学レベルの総合問題、VQA、多言語OCR、2D/3Dグラウンディング、動画理解など幅広いタスクで高評価を獲得し、Gemini 2.5 ProやGPT-5を上回る分野も確認されています。
Thinking版は数理推論・STEM領域で特に強く、MathVisionなどの複雑な課題でGemini 2.5 Proを超える精度を達成しています。一部タスクではクローズドモデルが優位な場面もありますが、2D/3D空間認識やエージェント操作では大きな強みを持っています。
Instruct版では「画像解析+ツール呼び出し」を組み合わせた推論機能を備え、複数の認識タスクで一貫した性能向上を確認できました。細部の物体認識や操作シーン分析など、実用的な応用領域でも成果を上げています。
また、テキスト中心のタスクにおいても、Qwen3-235B-A22B-2507(言語モデル)に匹敵する結果を記録し、視覚・言語の両面に偏らない総合的な理解能力を有しています。
Qwen3-VLのモデルの種類とAPI料金
Qwen3-VLシリーズは、モデルの規模や応答速度、思考(Thinking)能力の有無に応じて複数のバリエーションが提供されています。
大規模モデルほど精度や推論力が高く、Instruct版は高速・軽量な一般利用向け、Thinking版はより深い推論や分解思考を伴う応答に適しています。
利用目的に応じて、処理速度を重視するなら「Flash」や「Plus」、高度な分析・生成を重視するなら「Instruct」または「Thinking」を選択するのが一般的です。
以下の表では、各モデルのAPI利用料金を比較しています。
| モデル名 | 入力料金 (100万トークンあたり) | 出力料金 (100万トークンあたり) |
|---|---|---|
| Qwen3-VL-Plus | $0.20~$0.60 | $1.60~$4.80 |
| Qwen3-VL-Flash | $0.05~$0.12 | $0.40~$0.96 |
| Qwen3-VL-Plus-2025-09-23 | $0.20~$0.60 | $1.60~$4.80 |
| Qwen3-VL-Flash-2025-10-15 | $0.05~$0.12 | $0.40~$0.96 |
| Qwen3-VL-32B-Instruct | $0.16 | $0.64 |
| Qwen3-VL-32B-Thinking | $0.16 | $0.64 |
| Qwen3-VL-30B-A3B-Instruct | $0.0002 | $0.0008 |
| Qwen3-VL-30B-A3B-Thinking | $0.0002 | $0.0024 |
| Qwen3-VL-8B-Instruct | $0.00018 | $0.0007 |
| Qwen3-VL-8B-Thinking | $0.00018 | $0.0021 |
| Qwen3-VL-235B-A22B-Instruct | $0.4 | $1.6 |
| Qwen3-VL-235B-A22B-Thinking | $0.4 | $4.0 |
API料金は、随時変更の可能性があるので、公式サイトでご確認ください。
また、Qwen3-VL-PlusおよびQwen3-VL-FlashのAPI料金の詳細はこちらでご確認ください。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
Qwen3を使うには?
Qwen3-VLは、一般ユーザーから研究者・開発者まで幅広い層が利用できるように設計されています。利用方法は大きく以下の3つに分けられます。
- 「公式サイトやアプリを通じた利用」
- 「API利用」
- 「モデルダウンロード」
公式サイト・アプリから利用
一般ユーザーは「Qwen Chat」やモバイルアプリを通じて、すぐにQwen3を試すことができます。
公式サイト(https://chat.qwen.ai/)からアクセスでき、アカウントを作成しなくても基本的なチャット機能を利用可能です。翻訳や要約、多言語での会話といった幅広いタスクに対応しています。
ログインすれば履歴管理や高度な機能へのアクセスも可能となり、日常的な情報取得から学習・業務サポートまで幅広く活用できます。
APIから利用
公式で公開されているAPIを活用して、モデルを利用することが可能です。
モデルをダウンロードして利用
Hugging Face Transformers、ModelScope、Kaggleといったプラットフォームを通じてモデルを入手でき、すぐに実験や研究に利用可能です。
ローカル環境での運用にも対応しており、Ollama、LMStudio、llama.cpp、KTransformers、MLXなどのツールを用いれば軽量かつ柔軟に動作させられます。また、SGLangやvLLMを利用するとOpenAI互換のAPIエンドポイントを構築でき、既存のワークフローやサービスにスムーズに統合できます。
Qwen3-VLの活用事例
その一例として、X(旧Twitter)では以下のような投稿が共有されています。
ゲーム(スーパーマリオ)の解析
最近お気に入りのQwen3-VLを用いて、久々にプレイ👀
まあ、ありがちなミスりかたで終了、、、( ´ー`)y-~~そして、(学習データにも入っていないだろうし)適切に状況が認識できているとは思えない文言。
「敵(ゴーヤ)」ってなんぞや、、、😇 https://t.co/Sh3ZptJbcn pic.twitter.com/l3hEYt1qP3— 高橋 かずひと@パワポLT職人 (@KzhtTkhs) November 12, 2025
キャラクター再現能力
モデルはわかっているとはいえ、プロンプトだけでこれだけキャラを寄せることができる、Qwen3-VL-4B-Instructすさまじいな。
さすがQwen-ImageやQwen-Image-Edit2509のバックにあるだけはある。 pic.twitter.com/nAsO6jP2Os— Nobu-Kobayashi : Generative AI Technology (@nyaa_toraneko) October 25, 2025
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
Qwen3-VLについてよくある質問まとめ
- Qwen3-VLとは何ですか?
Qwen3-VLは、AlibabaのQwenチームが開発したマルチモーダルAIモデルで、テキスト・画像・動画を統合的に理解して推論・生成・実行ができる高度な基盤モデルです。
- どのモデルを選べばよいですか?
高速処理ならFlash/Plus、精度重視ならInstruct、複雑な推論が必要ならThinkingが適しています。用途に応じて使い分けるのが推奨されます。
まとめ
Qwen3-VLは、テキスト処理の強さと高度な視覚理解を統合し、知覚・推論・実行までを一貫して行えるマルチモーダル基盤モデルです。
Instruct/Thinkingの両モデルは、長文・長尺動画の解析、空間理解、コード生成、ツール連携、多言語OCRなどの多様な領域で高い性能を発揮し、オープンソースモデルとして新たなスタンダードを築きつつあります。
また、長コンテキスト処理、高精度な2D/3Dグラウンディング、ビジュアルエージェント操作といった領域でも優れた結果を示し、研究・教育・ビジネスまで幅広い実用シーンで活用が進んでいます。
Qwen3-VLは今後のマルチモーダルAIの発展を牽引する有力な選択肢として、注目が高まっています。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

