
【Meta】Omnilingual ASRとは?特徴、性能、料金プラン、利用方法まで徹底解説!
最終更新日:2025年11月13日

- 1,600以上の言語に対応し、500以上の低リソース言語に初めてAI文字起こしを実現したオープンソース大規模ASRモデル
- 少数の音声サンプルで新言語を追加可能なインコンテキスト学習により、固定言語セットを超えた拡張性を提供
- 7Bモデルは78%の言語でCER10%未満を達成し、Whisper Largeを大幅に上回る精度を実現
Omnilingual ASRは、1,600以上の言語に対応するMetaのオープンソース大規模自動音声認識モデルです。 従来のASRでは対応が難しかった低リソース言語にも文字起こしを提供し、世界中の言語コミュニティが音声技術を活用できる環境を目指して設計されています。
モデルは300M〜7Bまで幅広く揃えられ、少数のサンプルから新しい言語を追加できる柔軟な拡張性を持ち、研究・開発・地域支援など多様な用途で活用できます。
本記事では、Omnilingual ASRの特徴、性能、料金プラン、利用方法までを徹底的に解説します。
LLMに強い会社・サービスの選定・紹介を行います 今年度LLM相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 LLMに強い会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・GPT、Claude、Gemini、Llama等の複数モデルに対応
目次
Omnilingual ASRとは?
MetaのFundamental AI Research(FAIR)チームが開発したOmnilingual ASRは、1,600以上の言語に対応する大規模自動音声認識モデルのスイートです。これまで高リソース言語に偏りがちだったASR技術を見直し、500以上の低リソース言語にも初めてAIによる文字起こしを実現しました。
さらに、数例の音声とテキストを与えるだけで新たな言語を扱えるゼロショット適応(インコンテキスト学習)に対応しており、固定された対応言語セットにとどまらない拡張性を備えています。
また、350言語以上を収録した大規模音声データセット「Omnilingual ASR Corpus」も公開されており、研究者・開発者・地域コミュニティが言語技術を拡張するための基盤として活用できるようになっています。
Omnilingual ASRの特徴
Omnilingual ASRには、言語カバレッジ、モデル構造、運用形態、データ収集のそれぞれの側面で他のASRモデルとは明確に異なる特徴があります。ここでは、それらのポイントを整理して詳しく解説します。
1,600以上の言語に対応

Omnilingual ASRは1,600以上の言語を対象としており、そのうち500以上はこれまでAIによる文字起こしが存在しなかった低リソース言語です。
この規模は従来のASRモデルでは実現されておらず、データ量の少ない言語を含む幅広い領域にアクセス可能にしています。これにより、文字起こし技術が届いていなかった言語コミュニティにも利用の機会が生まれています。
少量サンプルで新たな言語を追加可能
Omnilingual ASRは、少数の音声とテキストのペアを提示するだけで、新しい言語の文字起こしを有効化できるインコンテキスト学習による拡張性を備えています。
従来必要とされた専門的な微調整や大量データを前提としないため、未対応言語の話者が自分たちの言語を容易にシステムへ持ち込める点が特徴です。これにより、特にデジタル資源の少ない言語での活用範囲が大きく広がります。
7B規模のwav2vec 2.0による大規模事前学習

モデルの基盤には、7BパラメータへスケールしたOmnilingual wav2vec 2.0が採用されています。このモデルは、大量の未転写音声を用いて自己教師ありで学習されており、多言語に共通して適用できる強力な音声表現を獲得しています。
これにより、大規模データのある言語だけでなく、データが限られた言語でも安定した音声特徴の抽出が可能になります。
CTC版とLLM-ASR版の2構成を提供
Omnilingual ASRは、異なる目的に対応するためにCTCデコーダ版とLLM-ASRデコーダ版の2種類を提供しています。また、LLM-ASRは大規模言語モデルの構造を採用したデコーダであり、特に多様性の大きい言語や長尾言語において性能を向上させています。
300M〜7Bまでの多サイズモデルを公開
Omnilingual ASRは、軽量な約300Mパラメータのモデルから7Bの大規模モデルまで複数のサイズが公開されています。
これにより、計算資源の限られた環境から高精度が必要な用途まで、利用者が目的に応じて最適なモデルを選択することができます。小規模から大規模まで揃えたスイート設計は、幅広いユースケースに適応するための重要な特徴です。
コミュニティ協力で構築された大規模コーパス
Omnilingual ASRには、世界各地のパートナーと協力して構築された「Omnilingual ASR Corpus」が含まれています。
これは350のアンダーサーブド言語で構成された転写音声データセットであり、地域組織がネイティブスピーカーをリクルートし、収録・転写を行うことで集められています。
また、Mozilla FoundationのCommon VoiceやLanfrica/NaijaVoicesとの連携など、言語コミュニティに寄り添ったデータ収集方法が採用されています。これにより、文化的背景や地域性を反映したデータをモデルに取り入れることが可能になっています。
参考:Omnilingual ASR: Advancing Automatic Speech Recognition for 1,600+ Languages
Omnilingual ASRの性能
Omnilingual ASRが示す音声認識精度と対応範囲の性能は以下のとおりです。
Omnilingual ASRの認識精度
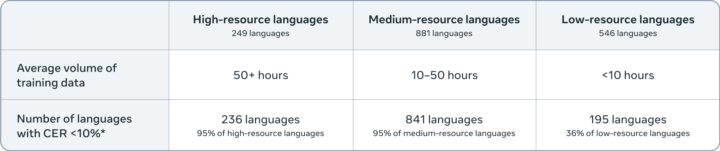
Omnilingual ASRの7B規模のLLM-ASRモデルは、対応する1,600以上の言語のうち78%でCER(文字エラー率)10%未満を達成しており、広範な言語にわたって高精度な音声認識性能を示しています。
特に、高リソース・中リソース・低リソースという3つのカテゴリ別に見ても、限られたデータ量の言語に対して実用的な精度を確保しています。
Whisperとのベンチマーク精度比較
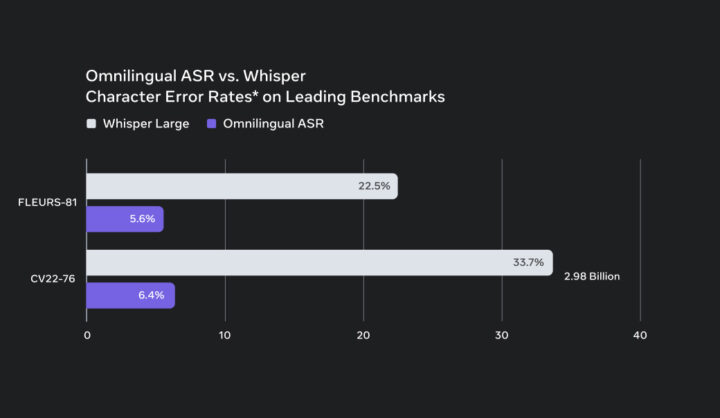
この図は、代表的なASRベンチマークであるFLEURS-81およびCV22-76における文字エラー率(CER)を比較したものです。Whisper LargeがFLEURS-81で22.5%、CV22-76で33.7%のエラー率を示す一方、Omnilingual ASRはそれぞれ5.6%、6.4%という低いCERを達成しています。
この結果は、Omnilingual ASRが既存の代表的モデルであるWhisper Largeと比較して、大幅に優れた認識精度を発揮していることを示しており、特に多言語領域での強力な性能が確認できます。
Whisperとの言語カバレッジ比較
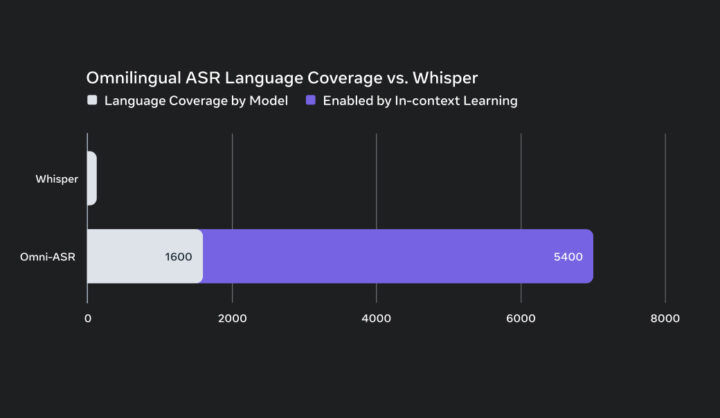
上記の画像は、Omnilingual ASRとWhisperが対応できる言語数を比較し、両モデルのカバレッジの差を視覚的に示したものです。Whisperは99言語を対象とする一方で、Omnilingual ASRはモデル自体が1600言語に対応しており、対応範囲に大きな差があります。
さらに、Omnilingual ASRはインコンテキスト学習によって追加の言語を扱うことができ、5400言語が拡張対象として示されています。
このことから、Omnilingual ASRは初期状態のモデルカバレッジに加えて、インコンテキスト学習による大幅な言語拡張性を持ち、既存のASRモデルと比べて圧倒的に広い範囲の言語を取り扱えることが分かります。
参考:Discover Meta Omnilingual Automatic Speech Recognition (ASR)
Omnilingual ASRのライセンス・料金体系
Omnilingual ASRは、モデル群がApache 2.0ライセンスで公開され、音声データセットであるOmnilingual ASR CorpusはCC-BYライセンスで提供されています。
これにより、研究者・開発者・コミュニティが自由にモデルの利用や再配布、改良を行えるオープンソース環境が整えられています。
Omnilingual ASRはGitHubで公開されているオープンソースプロジェクトとして提供されており、モデルファイルやデータセットをダウンロードして利用できます。
Omnilingual ASRのデモの使い方
Omnilingual ASRには、モデルの対応言語を確認したり、サンプルの文字起こし結果を閲覧したり、他モデルとの比較を行えるデモが用意されています。以下はデモで利用できる主な操作です。
対応言語を検索する
デモ上で、Omnilingual ASRが対応する1600以上の言語の中から、任意の言語を検索して選択できます。世界中の言語にどのように対応しているかを確認する最初のステップです。
文字起こし結果を確認する
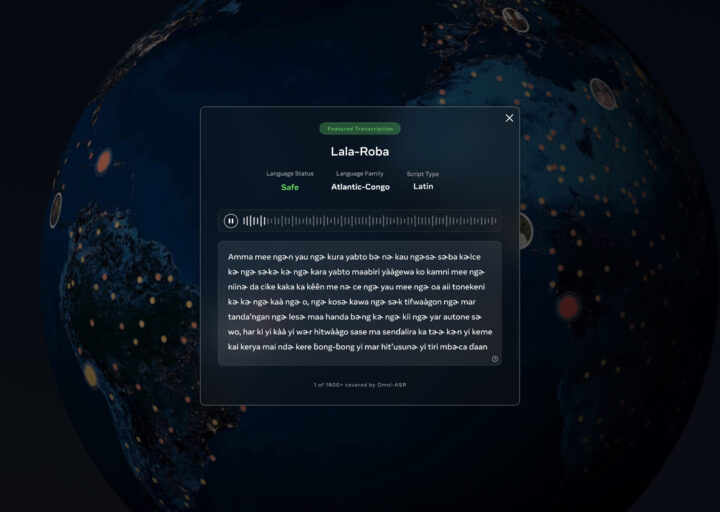
選択した言語について、実際のサンプル音声がどのように文字起こしされるのかを閲覧できます。モデルの出力例を通じて、各言語での認識性能を直接確認できます。
他モデルとのカバレッジ比較を見る
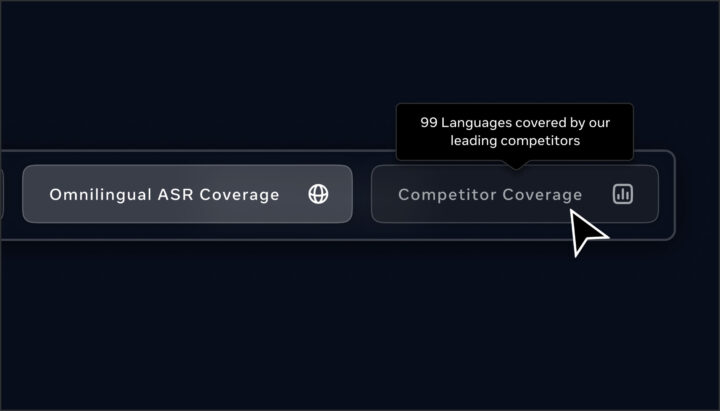
Omnilingual ASRが持つ言語カバレッジを、他の主要ASRモデルと比較することができます。対応言語数や拡張性など、競合モデルとの違いを視覚的に理解できる機能です。
Omnilingual ASRに関するよくある質問まとめ
- Omnilingual ASRはどのように新しい言語を追加できるのか?
Omnilingual ASRはインコンテキスト学習に対応しており、少数の音声とテキストのペアを提示するだけで新たな言語の文字起こしを有効化できる。
従来のASRモデルのように専門的な微調整や大量のデータ収集を必要としないため、未対応言語の話者が容易に自分たちの言語をシステムへ持ち込める設計となっている。
- Omnilingual ASRとWhisperの主な違いは何か?
Omnilingual ASRは1,600以上の言語に対応し、インコンテキスト学習により5,400言語への拡張が可能だ。
一方、Whisperは99言語に対応している。精度面では、FLEURS-81ベンチマークでOmnilingual ASRがCER5.6%を達成したのに対し、Whisper LargeはCER22.5%であり、大幅な精度改善を実現している。
まとめ
Omnilingual ASRは、1,600以上の言語を対象とするかつてない規模の自動音声認識モデルであり、500以上の未対応言語の文字起こしを可能にする点で大きな意義を持ちます。
大規模wav2vec 2.0の導入、CTCとLLMの二方式、スケーラブルなモデル構成、少量データからのゼロショット適応、広範なコーパス公開など、多角的に拡張された設計が特徴です。
オープンソースとして提供されていることは大きな利点であり、多様な言語コミュニティに音声技術への新たなアクセス手段を提供します。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、お客様の課題ヒアリングや企業のご紹介を実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

