
画像認識AIの精度向上ガイド!指標種類・低下の原因・改善方法・上げるコツを徹底解説
最終更新日:2026年03月28日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- 画像認識AIの精度は技術指標ではなく、閾値型の経営変数であり、投資回収の可否を左右します
- 精度低下の原因はモデル性能不足よりも、学習データの偏り・アノテーション品質・撮影環境条件という3層が絡み合って発生するケースが大半
- 精度改善は「データ設計の見直し→モデル選定・汎化強化→撮影環境の最適化→MLOpsによる継続運用」の順で取り組むことが基本
「デモでは99%の精度と言われたのに、現場では思うように動かない」という状況は、画像認識AIの導入プロジェクトで珍しくありません。この問題の本質は、検証環境(ラボ)と実運用環境(本番)の条件差にあります。
そしてその原因の多くは、モデルの性能不足ではなく、学習データの構成・アノテーション品質・撮影環境設計という開発の初期段階に起因しています。
本記事では、画像認識AIの精度が現場で低下する原因を「データ品質・モデル汎化・撮影環境条件」の3層で体系的に整理し、精度改善をデータ設計からMLOpsまでの7ステップで解説します。精度指標の正しい選び方、ベンダー評価のチェックポイント、PoCでの評価設計の落とし穴についても取り上げます。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識に強いAI開発会社をご自分で選びたい方はこちらで特集していますので併せてご覧ください。
目次
なぜ今まで以上に画像認識AIに精度が求められる?
画像認識AIの技術的な完成度は年々高まっています。しかし皮肉なことに、精度への要求水準も同じ速度で、あるいはそれ以上の速度で上昇しています。
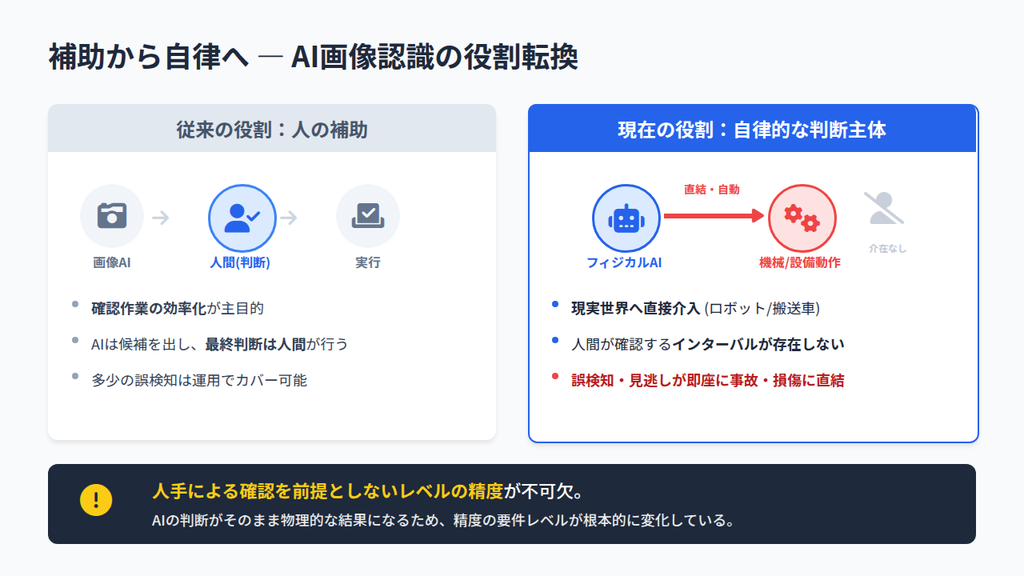
AIの役割が「人の補助」から「自律的な判断主体」へシフトしている
従来の画像認識AIは、主に人間の確認作業を効率化するための補助ツールとして設計されていました。不良品の候補を絞り込んで目視確認の負荷を減らす、監視カメラ映像の異常箇所をハイライトして警備員に知らせる、といった使われ方がその典型です。
この設計思想においては、AIが出した判断を最終的に人間がレビューすることが前提とされており、多少の誤検知は運用上の許容範囲内に収まっていました。
しかし近年、このパラダイムは大きく変わりつつあります。その変化を牽引しているのが、フィジカルAI(Physical AI)の台頭です。
フィジカルAIとは、デジタル空間での情報処理にとどまらず、ロボットや自動搬送車(AGV/AMR)、検査装置といった物理的なシステムと直接統合され、現実世界に働きかけるAIの総称です。
フィジカルAIにおいては、画像認識の結果がそのまま機械の行動に変換されます。人間がインターバルを挟んで確認する余地はありません。
誤検知や見逃しは、誤作動・設備損傷・作業員への危害へと直結します。
こうした「自律的な判断主体」としての役割を担うために、画像認識AIには人手による確認を前提としないレベルの精度が不可欠になっています。
精度の高低が投資回収の可否を決める経営変数になった
画像認識AIの精度を技術指標のひとつとして捉えている間は、その重要性は過小評価されがちです。しかし実際の導入現場では、精度の水準が事業経済性を根本的に左右する場面が増えています。
誤検知率が高ければ、アラートのたびに人が確認作業に入らざるを得ず、自動化による工数削減効果は大幅に損なわれます。見逃しが発生すれば、不良品の流出・返品・リコール対応といった事後コストが生じます。
さらに自律制御システムにおいては、誤判断が設備停止や事故に発展し、操業損失・修繕費用・コンプライアンスリスクをもたらします。これらはいずれも、導入前の投資試算には計上されにくいコストです。
逆に、精度が一定の閾値を超えた時点で、経済的な効果は非線形に拡大します。以下のような恩恵が連鎖的に実現するためです。
- 人の監視なしに24時間稼働できる
- 後工程への自動受け渡しが可能になる
- 複数ラインへの横展開が容易になる
つまり、精度は「高いほど良い」という連続的なグラデーションではなく、一定の水準を境に事業モデルそのものが変わる閾値型の変数です。画像認識AIの精度向上は、技術的な改善課題である以前に、投資回収の可否と事業設計の方向性を決める経営判断の問題といえます。
関連記事:「画像認識AIの導入・運用費用内訳を徹底解説!ROIの考え方と向上させる方法は?」
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識AIの精度を測る指標

画像認識AIの「精度」という言葉は、用途や評価者によって異なる指標を指していることがあります。同じシステムでも、何を基準に測るかによって数値の意味はまったく変わります。
基本的な精度指標とリスク感度
分類・検知系タスクで広く使われる基本指標は以下のとおりです。各指標が「何の誤りに敏感か」という観点で整理すると、業務上どれを優先すべきかが見えてきます。
| 指標 | 内容 | 業務上の意味と重視される場面 |
|---|---|---|
| 正解率(Accuracy) | 全予測に占める正解の割合 | データに偏りがある場合は過大評価になりやすいため、単独での使用は危険 |
| 適合率(Precision) | 「異常あり」と判定した件数のうち、実際に異常だった割合 誤検知の少なさを示す | 誤検知のたびにラインを止めて人が確認する工程では、誤報コストが直接的な損失になる。過剰アラートによる現場の「AIへの不信感」を防ぐ指標としても機能する |
| 再現率(Recall) | 実際の異常のうち、AIが検知できた割合 見逃しの少なさを示す | 医療画像診断、食品異物混入検査、インフラの亀裂検出など、1件の見逃しが重大なリスクに直結する用途で最優先される指標 |
| F1スコア | 適合率と再現率の調和平均 どちらか一方だけを最大化した場合のトレードオフを補正する | 誤検知も見逃しも両方コストになる汎用検査ラインや、複数クラスの分類を扱う用途での総合評価に適している |
物体検出・領域検出タスクに必要な追加指標
画像の中で対象物の位置を特定する物体検出(Object Detection)や、ピクセル単位で領域を分類するセグメンテーションのタスクでは、上記の分類指標だけでは精度を正確に評価できません。物体の「存在の有無」だけでなく、「どこに、どの大きさで存在するか」の正確さも評価する必要があるためです。
IoU(Intersection over Union)は、AIが予測したバウンディングボックス(検出枠)と正解枠の重なり面積の比率です。値が1に近いほど位置精度が高く、0.5以上を閾値とすることが多いです。
医療や精密部品検査などでは0.75以上が求められるケースもあります。
mAP(mean Average Precision)は、複数クラスのIoU精度を統合した総合指標で、物体検出モデルの比較評価で事実上の標準になっています。YOLOシリーズやDETRなど主要な物体検出モデルのベンチマーク結果はmAPで示されており、ベンダーが提示するモデル性能の比較に直接使える指標です。
自社の導入用途が物体検出を含む場合は、提案書やPoC報告書にIoUの閾値設定とmAPの値が明示されているかを確認することを推奨します。
ラボ精度と本番精度のギャップが、なぜプロジェクトリスクになるのか
画像認識AIの導入プロジェクトでよく起きる問題のひとつが、開発・検証段階では高精度を示していたシステムが、本番稼働後に期待どおりの効果を出せないケースです。この乖離の主な原因は評価環境と運用環境の条件差にあります。
開発時のラボ環境では、照明・撮影角度・背景・解像度が統制された状態でデータを収集します。そのため、高い精度指標が得られます。
しかし実際の製造現場や屋外インフラ環境では、以下のような変動要因が常に存在します。
- 光量の時間的変動
- カメラの経年劣化や位置ズレ
- 粉塵・汚れ・蒸気による視認性の低下
- 作業者や搬送物による一時的な遮蔽
この問題は技術的な失敗というより、評価設計の失敗として捉えるべきです。PoC(概念実証)やパイロット検証の段階で、本番環境を模した変動条件下でのテストセットを用意しているかどうかが、その後のプロジェクト成否を大きく左右します。
ベンダーから提示された精度数値を検討する際は「どのような環境・データで計測した値か」を必ず確認し、本番条件との差異を事前にすり合わせることが導入後の誤算を防ぐ最も効果的な手段のひとつです。
指標は技術要件ではなく業務リスクから選ぶ
精度指標の選定は、技術チームだけで決める事項ではありません。どの誤りがどれだけのコストや損失を生むかは業務上のリスク判断であるためです。
判断の基本的な問いは次の2つです。
- 誤検知(正常なのに異常と判定)が起きた場合、何が発生し、そのコストはいくらか
- 見逃し(異常なのに正常と判定)が起きた場合、何が発生し、そのコストはいくらか
この2つのコストを比較したうえで、より大きなリスクを抑制する指標を優先することが実運用で成果を出すための基本的な考え方です。
食品の異物混入検査のように「見逃しが製品回収・ブランド毀損に直結する」場合は再現率を最優先とし、誤検知による偽陽性コストはある程度許容する設計が合理的です。逆に、誤検知のたびにラインが止まり多大な機会損失が発生する高速生産ラインでは適合率を重視した閾値調整が必要になります。
精度指標の選択は、導入目的の定義と同じ重要性を持つ意思決定事項です。この判断を開発ベンダーに一任するのではなく、業務オーナーが自社のリスク優先順位を明確にしたうえでベンダーと合意しておくことがプロジェクト全体の品質を左右します。
画像認識AIの精度が低下する6つの原因
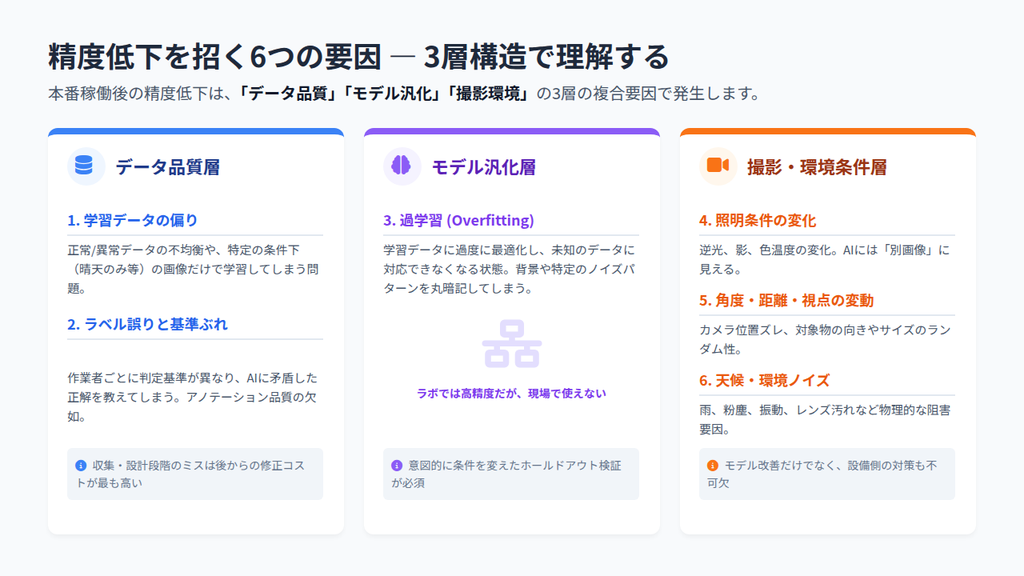
画像認識AIのプロジェクトで「PoCでは高精度だったのに、本番稼働後に期待した効果が出ない」という事態は珍しくありません。その原因の多くは、モデルの性能不足ではなく、データ品質・モデルの汎化設計・撮影・環境条件という3層の問題が絡み合って発生しています。
それぞれの原因を理解しておくことは、ベンダー選定の判断軸の整理、PoC設計の妥当性評価、そして導入後の運用設計に直接役立ちます。
【データ品質層】学習データの偏り
画像認識AIは、学習データが表現している世界しか理解できません。裏返せば、現場の多様性が学習データに十分に反映されていなければ、どれほど高性能なモデルを使っても本番精度は出ません。
典型的な偏りのパターンは以下のとおりです。
- 晴天時・日中の画像のみで学習 → 雨天・逆光・夜間で誤認識が急増
- 正面画像を中心に収集 → 斜め・俯瞰など角度が変わると精度が低下
- 特定の拠点・設備のデータのみ使用 → 他拠点への横展開で再現性が出ない
- 正常データが大量にある一方で異常データが極端に少ない → モデルが「正常」方向に引っ張られ、異常の見逃しが発生
最後の偏り(クラス不均衡)は特に見落とされやすく、正常品が99%を占める検査ラインでは、Accuracyが高くても異常の見逃し率が深刻に高いケースがあります。
学習データの偏りは収集段階の設計ミスであるため、後から修正するコストが高くなります。プロジェクト初期に「どのような条件バリエーションを網羅するか」を業務側とデータ担当者が合意しておくことが、精度トラブルの最大の予防策です。
【データ品質層】データラベルの誤りと基準のぶれ
学習データの「中身」に問題があるケースとして、アノテーション(ラベリング)の品質不足があります。精度低下の原因として見落とされやすい要因のひとつです。
主な発生パターンは以下です。
- 担当者によって良品・不良品の判断基準が異なる(同じキズが人によって別々にラベリングされる)
- 判定基準が文書化されておらず、熟練者の感覚に依存している
- 現場の検査ルールと学習用ラベルの定義が乖離している
画像認識AIは与えられたラベルを正解として学習します。基準がぶれていれば、モデルはその「ぶれ」ごと学習してしまい、精度は不安定になります。
この問題は、技術的な改善では解決できません。アノテーション前に判定基準を明文化し、複数人でのダブルチェック体制とラベル一致率の定期評価を仕組みとして組み込むことが必要です。
ベンダーへの発注時には、アノテーション品質管理のプロセスを確認することを推奨します。
【モデル汎化層】過学習(Overfitting)
「ラボでは高精度だが現場では使えない」という典型的なケースの根本原因が、過学習です。
過学習とは、モデルが学習データに過度に最適化してしまい、未知のデータへの対応能力(汎化性能)が失われた状態を指します。具体的には以下のような状態です。
- 対象物の本質的な特徴ではなく、背景・照明・フレームの特定パターンを覚えてしまっている
- 学習データのノイズやバリエーションの偏りをそのまま記憶してしまっている
- 評価データが学習データと近似しているため検証時に高精度が出るが、本番環境で未知のパターンに遭遇すると精度が急落する
過学習が起きている場合、検証指標を確認するだけでは発見できません。意図的に学習データに含まれない条件(別の拠点・別の時間帯・意図的に変化させた照明など)で評価するホールドアウト検証を設計段階から組み込むことが、過学習の早期発見に有効です。
精度評価の場面では「どのデータセットで測定したか」を常に確認し、学習データとの重複が疑われる場合は再評価を求める姿勢が、プロジェクト管理上の重要なチェックポイントになります。
【撮影・環境条件層】照明条件の変化
画像認識AIは画素情報をもとに特徴を抽出するため、人間の目には大した違いに見えない照明の変化でも、モデルにとっては「別物の画像」になりえます。
特に注意が必要な照明変動の例は以下です。
- 逆光や強い直射日光による輪郭消失・露出オーバー
- 夜間・暗所でのノイズ増加や色味の変化
- 照明の色温度差(昼光色・電球色など)による色調の変動
- 季節や時刻による自然光の入り方の変化(工場の窓の位置による影響も含む)
照明変動への対策は、モデル側(輝度変換・コントラスト調整などのデータ拡張)と環境側(照明設備の固定化・遮光対策)の両面から設計する必要があります。どちらか一方だけでは不十分なケースが多く、PoC前の撮影環境の調査と条件定義が重要です。
【撮影・環境条件層】角度・距離・視点の変動
カメラの設置位置が固定されていても、現実の運用ではわずかな変動が生じます。また、対象物のサイズや配置が毎回同一でない場合も多く、これらが精度低下の原因になります。
- カメラのわずかな傾きや経年による位置ズレ
- 被写体との距離変化によるサイズ・縮尺の違い
- 対象物の向きや姿勢の変動(ランダムな方向で搬送される部品など)
こうした変動に対しては、複数の角度・距離でデータを収集し、回転・拡縮・反転などのデータ拡張を活用することで、モデルの視点変動への耐性を高めることができます。カメラ設置の固定化と定期的なキャリブレーションも安定運用には欠かせません。
【撮影・環境条件層】天候・環境ノイズ(屋外・過酷環境)
屋外に設置されたカメラや粉塵・蒸気・振動が発生する工場環境では、環境ノイズが慢性的な精度低下要因になります。
- 雨・霧によるコントラスト低下と輪郭の消失
- 積雪による背景の大幅な変化
- レンズへの粉塵・油分・結露の付着
- 振動によるブレや解像度の実質的な低下
これらの問題への対処は、モデルの改善だけでは限界があります。悪天候・劣化条件を含めた学習データの設計、画像前処理パイプラインの整備、加えてカメラの定期清掃・防振マウント・保護ハウジングといった設備保守の仕組みを合わせて設計することが長期的な精度維持に不可欠です。
屋外環境や過酷な産業環境での導入を検討している場合は、ベンダーに対して「環境ノイズを含む学習データの取り扱い実績」と「ハードウェア保守要件の提案能力」の両方を確認することを推奨します。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
画像認識AIの精度改善方法

画像認識AIの精度改善において、最初に取り組むべきはモデルの変更ではありません。多くの場合、改善効果が大きい順に以下順序で対処することが費用対効果の高いアプローチです。
- データ設計の見直し
- 合成データ・Few-Shot学習による補完
- モデルの選定
- モデルの汎化強化
- 撮影・環境条件の最適化
- Active Learning によるデータ拡充
- 継続運用の仕組み化
モデルをいくら高度化しても、学習データの品質や撮影環境に根本的な問題があれば精度は頭打ちになります。以下では、この順序に沿って具体的な改善手法を解説します。
1:学習データの質・量・構成の見直し
精度改善の出発点は常にデータです。「モデルを変えても精度が改善しない」という場合、原因の多くはデータ側にあります。
まず確認すべきは、クラス不均衡の有無です。異常検知タスクでは正常データが9割以上を占めるケースが一般的で、この状態を放置するとモデルは「正常」方向に偏り、見逃し率が高止まりします。
| 課題 | 具体的対策 | 適用の目安 |
|---|---|---|
| データの偏り | 天候・時間帯・角度・拠点ごとのデータを追加収集 | 本番環境と学習データの撮影条件に乖離がある場合 |
| クラス不均衡 |
| 正常:異常の比率が10:1以上の場合 |
| データ不足 |
| 収集可能な実データが数百枚以下の場合 |
| アノテーション品質のぶれ |
| 担当者間で良品・不良品の判断が割れている場合 |
2:合成データ・Few-Shot学習による希少ケースの補完
実データだけでは補いきれない希少なパターン(レアな不良形状・再現困難な事故状況など)については、合成データや少量データでも機能する学習手法の活用が有効です。
合成データ生成では、照明・角度・背景・天候などの変動条件を人工的に作り出し、実環境に近いデータ分布を再現します。GANやDiffusion model(拡散モデル)を使った高品質な画像生成も実用フェーズに入っており、外観検査領域では合成不良画像の品質が実データに迫るケースも出てきています。
デジタルツインと組み合わせれば、現場投入前にモデルの挙動検証を仮想環境で完結させることも可能です。
ただし、合成データのみで学習するとドメインギャップ(合成と実環境の分布差)が生じやすいため、実データとの混合学習が基本です。
Few-Shot学習・基盤モデルの活用も、データ不足環境への対応として注目されています。
Meta社が開発した「Segment Anything Model(SAM)」やMicrosoft・Metaが公開している自己教師あり学習モデル「DINOv2」は、少量の実データでファインチューニングするだけで、高い汎化性能を発揮することが多数の産業用途で検証されています。
3:AIモデルの選定
データ設計が整ったうえで、次にモデル側の改善に取り組みます。モデルアーキテクチャの選定においては、タスクの性質・データ量・処理環境に応じてCNNとVision Transformer(ViT)を使い分けることが基本になります。
| 比較項目 | CNN | Vision Transformer(ViT) |
|---|---|---|
| 特徴抽出の方向性 | 畳み込み層で局所特徴を段階的に抽出 | 画像をパッチ分割し、Self-Attentionで画像全体の関係性を把握 |
| 強み | 局所的なテクスチャ・形状パターンの検出に強い | 画像全体の構造・文脈理解に強い |
| 必要なデータ量 | 少量でも安定しやすい | 大規模データで真価を発揮(基盤モデルとの組み合わせで小規模でも可) |
| 計算負荷 | 軽量化しやすく、エッジデバイス向き | 計算量が多く、高性能GPUサーバー向き |
| 代表的な用途 | 産業外観検査、監視カメラ、リアルタイム物体検出 | 医療画像診断、複雑シーン分類、高精度解析 |
近年はCNNとTransformerの設計思想を融合したハイブリッドアーキテクチャ(ConvNeXt、EfficientViTなど)も実用化が進んでいます。エッジ環境での高速推論と高精度を両立したい場合の有力な選択肢として、ベンダーに提案実績を確認する価値があります。
異常検知に特化したアーキテクチャとしては、PatchCoreやEfficientADが産業検査領域で注目されています。これらは少数の正常画像だけを学習して異常を検出するアプローチを採用しており、異常データの収集が困難な現場での実績が積み上がっています。
4:AIモデルの汎化強化
「ラボでは高精度なのに現場で使えない」という典型的な状況は過学習と汎化設計の不足が主因です。
| 改善方向 | 具体的手法 | 効果・適用場面 |
|---|---|---|
| 過学習の防止 |
| 学習データへの過剰適合を抑制し、未知データへの耐性を高める |
| 評価設計の改善 |
| 過学習の早期発見。学習データに含まれない条件で意図的に評価する |
| 転移学習の活用 | ImageNet・大規模データセット事前学習済みモデルのファインチューニング | データ不足環境でも高い初期精度を実現。学習コストを大幅に削減できる |
| アンサンブル学習 | 複数モデルの予測を統合して最終判定 | 単一モデルの誤判定リスクを分散。高信頼性が求められる検査用途に有効 |
5:撮影・環境条件の設計最適化
モデルとデータの改善と並行して、物理的な撮影環境の最適化を行うことで、精度の安定性が大幅に向上します。特に照明とカメラ設置は、AIが処理する画像の品質を根本的に左右するため、後から変更すると再学習コストが発生します。PoC段階から撮影環境の仕様を固めておくことが重要です。
| 対象 | 具体的対策 | 効果 |
|---|---|---|
| 照明の安定化 |
| 照明変動による特徴量のぶれを抑制し、推論精度が安定する |
| カメラ位置・角度の固定 |
| 視点変動による誤認識を防ぎ、長期的な精度維持に貢献する |
| 振動・汚染対策 |
| ブレや汚れによる実効解像度の低下を防ぐ |
6:Active Learning による継続的なデータ拡充
本番稼働後にモデルが苦手とするケースを効率的に特定し、優先的に再学習データへ取り込む仕組みとしてActive Learning(能動学習)が実用フェーズに入っています。
Active Learningでは、モデルが判断に迷っているサンプル(予測確率が閾値付近のケース)を自動的に抽出し、アノテーション対象として優先的に提示します。ランダムに追加データを収集するよりも少ないアノテーションコストで、精度改善の効果が得られることが多数の研究・実装事例で確認されています。
特に誤検知・見逃しが発生したサンプルを優先的にフィードバックループに取り込む設計は、実運用環境に即した精度改善として最も効果が高いアプローチのひとつです。
7:MLOps による継続的な再学習サイクルの構築
精度改善は一度の開発で完結するものではありません。現場環境は時間とともに変化し、製品仕様・照明設備・搬送方式の変更がモデルの性能劣化を引き起こします。これに対応するには、継続的な再学習と評価のサイクルを自動化するMLOpsの仕組みが不可欠です。
MLOpsパイプラインの主要な構成要素は以下のとおりです。
- データ収集・監視
- ドリフト検知
- 再学習パイプライン:誤検知・見逃し事例を優先的に取り込んで学習セットを更新し、自動的にモデルを再訓練するフロー
- 評価・デプロイ管理
この仕組みを整備することで、属人的なモデル更新作業を排除し、環境変化に適応し続ける画像認識AIの長期的な運用品質を担保できます。
MLOpsパイプラインの設計・構築は、社内にMLエンジニアとインフラ担当が揃っていても実装経験のない組織には相応のハードルがあります。こうした場合、画像認識領域のMLOps構築に実績のある外部パートナーに設計フェーズから関与してもらうことで構築期間の短縮と品質リスクの低減が見込めます。
AI Marketでは、製造・物流・インフラを含む画像認識AIの累計1,000件以上の相談実績をもとに、MLOps対応の実績がある開発会社をコンサルタントが要件を整理したうえで紹介しています。「自社のどのステップを委託すべきか」が明確でない段階での相談も受け付けており利用は無料です。
外注・専門パートナーの活用
上記を自社だけで実施するには、データエンジニアリング・MLエンジニアリング・MLOps構築それぞれの専門知識が必要です。社内リソースに不足がある場合、AI開発の専門会社への外注が精度改善の最短経路になることが多いです。
特に以下の場面では、外部専門家の知見が有効に機能します。
- 現状の精度低下原因の診断(データ・モデル・環境のどこに問題があるか)
- アノテーション基準の設計とラベリング品質管理の仕組み化
- タスク特性に合ったアーキテクチャ選定と実装(PatchCore・EfficientAD・ViTハイブリッドなど)
- MLOpsパイプラインの設計と継続運用支援
PoC段階のみの支援・データ整備の部分委託・モデル構築から運用までの包括支援など自社の体制と課題フェーズに応じて委託範囲を選択できます。依頼前に「自社課題のどのステップに相当するか」を明確にしておくと、ベンダーとの要件整合がスムーズになります。
画像認識AIの精度についてよくある質問まとめ
- デモでは高精度だったのに、なぜ現場では精度が下がるのですか?
原因は「データ品質・モデル汎化・撮影環境条件」の3層に分けて整理できます。
- データ品質層:特定条件のみの学習データ(晴天・正面・特定拠点のみなど)によるデータ偏り、クラス不均衡(正常:異常=99:1など)、アノテーション基準のぶれ
- モデル汎化層:学習データへの過剰適合(過学習)。検証データと学習データが近似しているため検証時は高精度が出るが、本番の未知パターンで精度が急落する
- 撮影・環境条件層:照明の時間的変動、カメラの経年位置ズレ、粉塵・蒸気・振動による視認性低下
PoCと本番の条件差が原因の場合、これは技術的な失敗ではなく評価設計の失敗として捉えるべきです。
- 精度低下の原因がデータなのかモデルなのか環境なのか、自社では判断できません。どうすればいいですか?
原因の切り分けは、画像認識AI改善プロジェクトの中で最も専門的な判断が求められるステップのひとつです。判断の手がかりとして、まず「PoCと本番の撮影条件が一致していたか」「誤検知・見逃しのサンプルにパターンがあるか(特定条件下に集中しているかランダムか)」を確認することが出発点になります。
ただし、これらを自社だけで体系的に診断するには相応の経験が必要です。AI Marketでは、画像認識領域を含む累計1,000件以上の相談実績をもとに、AIコンサルタントが要件・課題をヒアリングしたうえで、精度改善の診断から対応できる開発会社を1〜3営業日程度で紹介しています。要件が固まっていない段階での相談も受け付けており、利用は無料です。
- 画像認識AIの精度はどのような指標で評価すればよいですか?
タスクの種類によって使うべき指標が異なります。
- 正解率(Accuracy):全体の正解割合。データに偏りがある場合は過大評価になるため単独使用は危険です。
- 適合率(Precision):誤検知の少なさを示す指標。誤報ごとにラインが止まる工程で重視します。
- 再現率(Recall):見逃しの少なさを示す指標。食品異物検査・医療診断・インフラ点検で最優先です。
- F1スコア:適合率と再現率の調和平均。総合的な評価に使います。
- IoU・mAP:物体検出・セグメンテーション用の位置精度指標。ベンダー提案書に明示されているか確認してください。
指標は技術要件ではなく「どちらの誤りがより大きなコストを生むか」という業務リスクの観点から選ぶことが原則です。
- 社内に画像認識AIの開発経験者はいますが、MLOpsの設計・構築の知識が不足しています。部分的な委託はできますか?
対応できます。MLOpsパイプラインは、設計・構築・運用のすべてを委託することも、「パイプライン設計のみ」「再学習フローの構築のみ」といった部分委託も可能です。委託前に「自社で担う範囲(データ収集・アノテーション・推論環境の保守など)」と「外部に依頼する範囲」を切り出しておくと、ベンダーとの要件整合がスムーズになります。
AI Marketでは、こうした委託範囲の切り出し自体もコンサルタントが一緒に整理し、MLOps構築の実績がある開発会社を複数社紹介しています。問い合わせ後に複数社から一斉に連絡が届く仕組みにはなっておらず、紹介後は希望した会社のみと接続する設計のため、社内の調整負荷を増やさずに選定を進めることができます。
まとめ
画像認識AIの精度は、業務効率やコスト削減、リスク低減に直結する要素です。
精度低下の原因は、モデル性能だけでなく、データの偏りやラベルの誤り、照明・カメラ環境、過学習、運用設計など多方面にあります。
精度を高めるには、データ設計の見直しやモデルの適切な選定、物理環境の最適化、MLOpsによる継続的な再学習が不可欠です。
現状の精度低下の原因がデータなのかモデルなのか環境なのかを診断する段階から、「自社だけでは判断が難しい」と感じている場合は、AI開発の専門パートナーへの相談が改善への最短経路になります。
AI Marketでは、画像認識領域を含む累計1,000件以上の相談実績をもとに、要件が固まっていない段階からコンサルタントが課題を整理し、1〜3営業日程度で適切な開発会社を無料で紹介しています。問い合わせ後に複数社から一斉に連絡が届く仕組みにはなっていないため、自社のペースで選定を進めることができます。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

