
Segment Anything Model 3とは?テキスト指示で物体検出を行う仕組み・実画面付きの使い方まで徹底解説!
最終更新日:2025年12月08日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- SAM 3は画像・動画内の任意オブジェクトを高精度に検出・セグメント・追跡できる統合モデル
- テキスト、例示(Exemplar)、クリックによる視覚プロンプトに対応し、複雑な対象指定にも柔軟に対応
- Segment Anything Playgroundで誰でも無料で利用可能
Metaは2025年11月19日、画像や動画内の任意のオブジェクトを高精度に検出・セグメント・追跡できる画像認識モデルSegment Anything Model 3(SAM 3)を発表しました。
テキスト、例示(Exemplar)、クリックによる視覚的プロンプトに対応し、従来のSAMシリーズを進化させたモデルです。Segment Anything Playgroundを通じて誰でも利用でき、創造的なメディア編集や研究、産業活用を含め幅広い領域での応用が期待されています。
本記事では、SAM 3の概要・できること・仕組み・性能・実際の操作画面、操作動画付きの使い方まで徹底的に解説します。
画像認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
目次
Segment Anything Model 3とは?
Meet SAM 3, a unified model that enables detection, segmentation, and tracking of objects across images and videos. SAM 3 introduces some of our most highly requested features like text and exemplar prompts to segment all objects of a target category.
Learnings from SAM 3 will… pic.twitter.com/qg43OtDyeQ
— AI at Meta (@AIatMeta) November 19, 2025
Segment Anything Model 3(SAM 3)は、画像や動画におけるオブジェクトの検出・セグメント・追跡を、テキスト、例示、視覚プロンプトを基に実行できるオープンソースのAIモデルです。
従来の固定ラベルに依存するセグメンテーションでは対応できなかった複雑な概念を扱うことが可能であり、任意の物体を柔軟に識別できる点が特長です。
例えば、「犬を検出してXXXして」とプロンプトを入力することで、動画中の犬を検出して任意のエフェクトをつけることが可能となります。
Metaは、Segment Anything Playgroundという誰でも簡単にモデルを試せる環境の他、モデルウェイトの公開、研究用データセットとファインチューニングコードの提供を通じて開発者と研究者が活用しやすい環境も提供しています。
SAM 3の料金
SAM 3はオープンソースのモデルであるため、プレイグラウンドで使用する場合でも、モデルをダウンロードして使用する場合でも料金は一切かかりません。
同時リリースのSAM 3D
画像から3Dモデルを構成するSAM 3DはSAM 3と同時にリリースされています。こちらも、SAM 3同様Segment Anything Playgroundから利用することができます。
詳しくは、別の記事で詳しく解説する予定ですので、そちらも是非ご参照ください。
画像認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
ここがすごい!SAM 3の仕組みとは?
SAM 3は、テキスト、例示、視覚プロンプトを統合的に扱う新しいアーキテクチャを採用し、画像と動画の両方で統一されたセグメンテーション処理を実現しています。複数のタスクを単一モデルで高精度にこなすため、学習方法とモデル設計に工夫が加えられています。
データエンジン(学習)
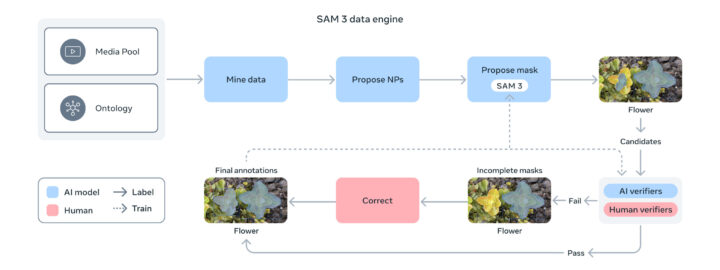
SAM 3の開発では、広範な概念と多様な視覚領域をカバーする高品質データを確保するために、AIと人間のアノテーターを組み合わせたスケーラブルなデータエンジンが活用されています。
従来のSAM(SA-1Bデータセット)はマスク数は10億以上と膨大でしたが、クラスラベル(それが何であるか)は付与されていませんでした。
そこで、主にLlamaベースのキャプショニングモデルなど複数のAIが、画像や動画から自動的にキャプション生成と初期セグメンテーションマスクの生成を行います。これにより、400万種以上の概念ラベルを付与しており、これが「テキスト指示で何でも切り抜ける」機能の源となっています。
そして、人間とAIのアノテーターがその精度を検証し修正するフィードバックループによってデータ品質を継続的に改善します。
負例(Negative)で5倍、正例(Positive)で36%の高速化
上記の仕組みにより、約400万以上のユニーク概念を含む大規模データセットが効率的に構築され、従来の人手作業のみのアノテーションに比べて、負例では約5倍、正例では約36%の高速化を実現しています。
特に、負例(Negative)の高速化が重要です。これまでのモデルは「ないものを『ない』と判断する」のが苦手で、無理やり何かを検出しようとしてハルシネーション(誤検知)を起こしていました。
「画像内に『錆びたボルト』はない」という不在の判定を効率的に学習データに組み込めたことが、実務での信頼性向上(誤検知の減少)に直結しています。
モデルアーキテクチャ(設計)
SAM 3は、単なるセグメンテーションモデルではなく、検出(Detection)、セグメンテーション、追跡(Tracking)を統合したモデルです。
Detector & Tracker
画像レベルの検出器と、ビデオレベルの追跡器が、共通のバックボーンを共有しています。これにより、計算リソースを無駄にせず、高速な処理が可能です。
Promptable Concept Segmentation (PCS)
テキストや画像プロンプトを入力として、対象となる「概念」全体をマスクするタスクです。SAM 2と比較して、このタスクでの精度は約2倍に向上しています。
Presence Head(存在判定ヘッド)
従来のモデルは、無理やり何かを見つけようとしてハルシネーション(幻覚:ないものをあると判定する)を起こす傾向がありました。 SAM 3では、対象がそのフレームに存在するかどうかを判定する「Presence Head」が導入されました。
False Positive(誤検知)を抑制できるので、疎な(対象が少ない)フレームが続くような監視業務でも高い信頼性を出せます。
メモリ機構の継承と進化
SAM 2で導入された「Memory Mechanism(過去のフレーム情報を記憶する仕組み)」はSAM 3でも健在です。これにより、対象物が一時的に隠れて、再び現れても、同一物体として認識し続けます。
画像認識に強いAI会社の選定・紹介を行います
今年度AI相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
SAM 3でできること
以下ではSAM 3でできることをご紹介していきます。
テキストやGUIによる対象指定
短い名詞句で対象を指定し、マッチするオブジェクトを自動検出・セグメントできます。説明語句にも対応しているため、例えば「ストライプ柄の赤い傘」など複雑な対象も検出可能です。
テキスト表現だけで高精度な領域抽出を実現しています。
また、対象の例を囲むだけで、同一カテゴリの他オブジェクトを抽出できます。複数登場する物体の一括処理に適しています。
他にも、クリックすることで対象を指定可能で、直感的に使いやすい設計になっています。
動画で対象を選択した場合は、リアルタイム追跡を行ってくれます。
視覚プロンプトによるインタラクティブ操作
対象の選択が不適切だった場合はクリックで微調整が可能で、見逃しや誤りを修正できます。
例えば、上の動画のように選択されて欲しくないものまで選択されてしまったときに、対象から外したいオブジェクトをクリックすることによって選択範囲を修正することができます。
エフェクトの追加
選択された対象や背景に対してエフェクトを追加することができます。上の動画は、犬に対して色によるハイライトとモザイクをかけたものになります。
使用できるエフェクトは、ボックスや絵画風・色見の変更など他にも多数あり、パラメータによる細かい調整ができるものも多くあります。
作成した動画はシェアやダウンロードすることも簡単にできます。将来的には、Instagram Edits、Meta AI Vibesなどでの実装が予定され、動画編集や生成AI映像加工に活用されると考えられます。
画像認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 画像認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
・物体検出、異常検知、類似画像検索等
SAM 3の性能ベンチマーク
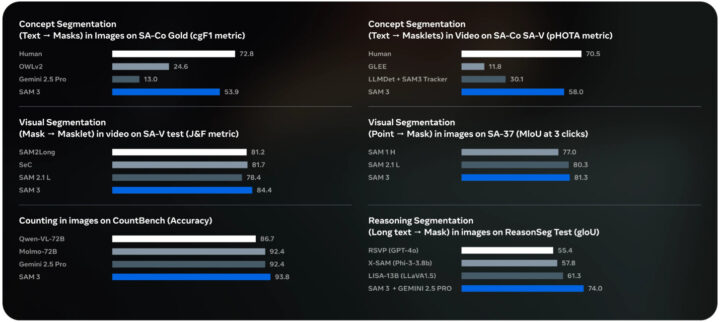
SAM 3は、画像と動画の概念セグメンテーション性能において高い性能を誇っています。
画像ではSA-Co Goldサブセット、動画ではSA-Co Videoを用いた評価です。既存システムと比較してcgF1スコア(概念の認識と位置特定の精度を表す指標)をおよそ2倍に向上させています。
さらに、Gemini 2.5 Proのような基盤モデルやGLEE、OWLv2、LLMDetといった強力な専門モデルと比較しても一貫して優れた結果を示しています。ユーザー調査では最強ベースラインとされるOWLv2に対して、SAM 3の出力が約3対1の割合で好まれています。
SAM 3は、SAM 2で導入された視覚セグメンテーションタスク(mask-to-maskletやpoint-to-mask)においても最先端の結果を達成し、SAM 2と同等あるいはそれ以上の性能を維持しています。
この高い精度は推論速度の速さと両立しており、SAM 3はH200 GPU上で100個以上のオブジェクトを含む単一画像を約30ミリ秒で処理できます。動画においても、おおよそ5つのオブジェクトを同時に扱う場面でリアルタイムに近い応答速度を維持できる設計になっています。
SAM 3の使い方
SAM 3にはプレイグラウンドと、モデルをダウンロードしローカル環境で実行するという二つの使用方法があります。
Segment Anything Playgroundでの利用
Segment Anything Playgroundでの利用はログインも必要なく、誰でも簡単にSAM 3を試してみることが可能です。
今回は、動画を例に取り使い方を説明していきます。やることは大まか3ステップで、「1. 動画の追加」、「2. オブジェクトの選択」、「3. エフェクトの追加」です。
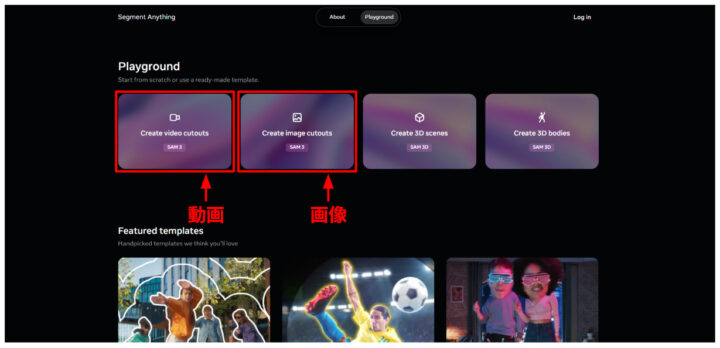
- Segment Anything Playgroundにアクセスすると以下のような画面になるので、画像か動画かお好きな方をご選択ください。
- 動画を選択し、以下のような画面になったら、まず動画の追加をしましょう。
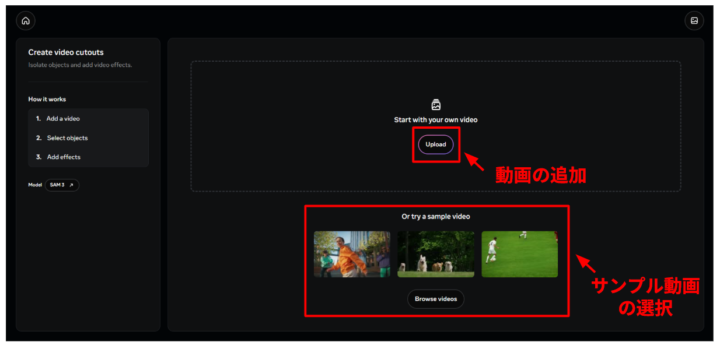
- 使いたい動画がある方は、「Upload」から動画を追加、特にない方はサンプルビデオから選択しましょう。
今回は、サンプルビデオから犬が走ってくる動画を使用していきます。 - 対象の選択を行っていきます。以下の動画のように、左のテキストボックスから選択したいものの名前を入れることで選択することができます。
テキストプロンプトによる対象の指定 オブジェクトの選択ができたら、画面左下の「Preview frame」をクリックすることで動画の間中、追跡してくれていることが確認できます。今回のように鼻という身体の一部分を対象とすることも可能で、精度もかなり高いことがわかります。
- 動画を再生しきると以下のような画面となり、オブジェクトの削除や「Add object」を押すことでポイント&クリックによるオブジェクトの追加・修正が可能となります。
なお、以降の操作をわかりやすくするために、対象を犬全体に変更しています。

- 画面左下の「Continue to effect」をクリックすると、エフェクトの設定に進むことができます。「Update result」ボタンが表示されている場合は、一度そちらをクリックすると「Continue to effect」に変わります。
- 以下の動画のように、画面左の「Add effect」から好きなようにエフェクトを追加することができます。エフェクトは重ねがけができる組み合わせがあるだけでなく、オブジェクトと背景双方にかけることもできます。
エフェクトの追加
できた動画は、画面左下の「Share」からダウンロードすることが可能です。
モデルをダウンロードし使用
モデルウェイトやファインチューニングコードが公開されており、研究や開発用途でローカル環境に導入して利用できます。こちらのGithubからダウンロードすることで使用することができます。詳しい手順などは、Githubをご参照ください。
注意点として、以下が前提条件として挙げられているのでご確認ください。
- Python 3.12以上
- PyTorch 2.7以上
- CUDA 12.6以降を搭載したGPU
SAM 3についてよくある質問まとめ
- SAM 3とは?
SAM 3(Segment Anything Model 3)は、Meta AIがリリースしたオープンソースの画像・動画のセグメンテーションモデルです。
テキストや視覚プロンプトを使ってオブジェクトを検出・分割・追跡することが可能です。概念的なプロンプトにも対応可能で、検出精度が高いことが特長として挙げられます。
- SAM 3が従来のSAMシリーズと違う点は?
テキストプロンプトと例示プロンプトに対応し、任意の概念や複数対象を同時にセグメント可能になった点が大きな進化です。
また、動画内の追跡精度も強化されています。
まとめ
SAM 3は、テキスト、例示、視覚プロンプトを統合したセグメンテーションモデルで、従来のモデルと比較して画像や動画におけるオブジェクト抽出と追跡の精度と柔軟性が向上しています。
Instagram EditsやMeta AIアプリなど実用領域でも活用が進み、創作や研究の可能性を広げる重要な技術基盤となることが期待されます。
「専用のAIを作る」前に、「SAM 3で一旦やってみる」。 このアプローチが、新規事業の立ち上げスピードを劇的に加速させるはずです。
貴社の現在の課題(製造ラインの検品、動画データの整理、アノテーションコスト削減など)に対し、SAM 3がどの程度「そのまま」使えるか、まずは既存の動画データを使って技術検証(PoC)の計画を立ててみませんか?

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

