
AIエージェントの評価指標は?主要フレームワークと観測ツールの機能比較を解説!
最終更新日:2026年02月16日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- AIエージェントは単発の回答精度ではなく、ツール利用や意思決定を含むタスク完遂までのプロセスを多層的に評価する必要
- 無限ループによるコスト増大やセーフティ・ポリシー違反など最終出力だけでは見えない運用上の失敗を指標化することが不可欠
- 評価環境の固定化(モック化)やCI/CDへの統合により、属人的な検証を排し、継続的に性能を改善できる「評価パイプライン」を構築する
生成AIの活用が「検索や要約」から「業務の自律的遂行」へとシフトする中で、多くの企業が直面しているのが、AIエージェントの品質をどう保証するかという難題です。
特にAIエージェントは、マルチターンで会話や行動が分岐し、同じ入力でも異なる経路をたどるため、従来の生成AI評価手法では十分にテストできません。タスク完遂率をどう定義するのか、誤ったツール実行や無限ループをどう検知するのかといった点は多くの現場で課題となるでしょう。
本記事では、AIエージェント評価が難しいとされる理由から、評価における観点、タスク完遂率の定義、代表的な評価フレームワークや評価ツールを解説します。AIエージェントを本格的に業務へ導入・運用したいと考えている方は、ぜひ参考にしてください。
AIエージェントに強い会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 AIエージェントに強い会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
AI開発会社をご自分で選びたい方はこちらで特集していますので併せてご覧ください。
目次
AIエージェントの評価が従来生成AIと比較して難しい要因は?
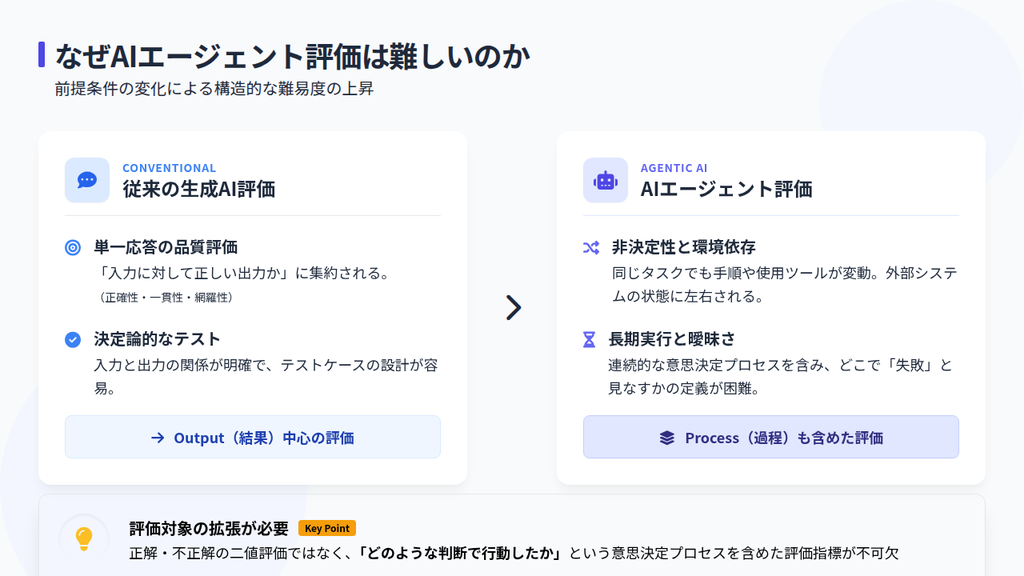
AIエージェントの評価は、難易度が高い領域とされています。その背景には、従来の生成AI評価で前提とされてきた条件がエージェントには当てはまらないという構造的な違いがあります。
関連記事:「AIエージェントと従来システムの導入プロセスの違いは?」
従来の生成AIとAIエージェントにおける評価対象の相違点
従来の生成AI評価は、主に「入力に対してどのような出力が返ってきたか」という単一応答の品質を測定することに主眼が置かれてきました。RAGを含む生成AIでは、回答の正確性・一貫性・網羅性など評価対象は最終的なテキスト出力に集約されます。
この前提では、入力と出力の関係が明確であり、テストケースも決定論的に設計しやすいという特徴があります。
一方でAIエージェント評価は、この前提が成り立ちません。AIエージェントはタスク達成を目的とした連続的な意思決定プロセスを内包してるので以下のような特徴があります。
- 非決定性: 同じタスクでもステップ数や利用するツールが変動する。
- 環境への依存: 連携先のSaaSのレスポンスやDBの状態に左右される。
- 長期実行性: 数分〜数時間に及ぶタスクにおいて、どこで「失敗」と見なすかの定義が難しい。
ユーザーとのマルチターンの対話、外部ツール・APIの呼び出し、環境状態の変化を踏まえた判断といった要素が絡み合い、評価対象は出力から行動の過程へと拡張されます。
結果として、正解・不正解の二値評価ではなく、どのような判断がどの段階で行われたのかを含めた多面的な評価が求められるのです。
AIエージェントの実運用で想定される事故パターンと評価設計の見落とし要因
AIエージェントの評価が難しい理由は理論面だけではありません。実運用において評価設計が不十分なまま導入されることで、見逃されやすい事故や障害が発生しやすい構造を持っています。
以下では、AIエージェント評価において事故が起きやすいポイントと評価上の見落としやすさをまとめています。
| 事故が起きやすいポイント | 内容 | 見落とされやすい理由 |
|---|---|---|
| 誤ったツールの実行 |
| 最終出力が正しければ問題なしと判断されがち |
| 不要なアクションの連鎖 |
| 成功・失敗の二値評価では検知できない |
| 無限ループ | 同じ判断や会話を繰り返し、終了条件に到達しない | テストが途中で打ち切られ、原因分析が行われない |
| 人間介入の多発 | Human-in-the-loopが頻発し、自律動作が成立しない | 人が修正する前提で評価が甘くなる |
| セーフティ・ポリシー違反 |
| 正常系テストでは表面化しにくい |
| コストの異常増大 | トークン消費やAPI呼び出しが想定以上に増加する | 品質評価とコスト評価が分離されがち |
これらの事故に共通する特徴として、ゴールが達成されたかどうかだけでは判断できない点にあります。たとえ最終的にゴールに到達していたとしても、その過程で過剰なコストを消費したり、危険な判断を行ったりしている可能性があります。
そのため、AIエージェント評価においては、行動単位・ターン単位での失敗分析や、誤ツール実行、無限ループ、安全違反といった観点をあらかじめ評価項目として定義することが不可欠です。
評価を設計しないまま運用に投入すると、AIエージェントは動いているが、安全かどうか分からない状態が量産されることになるでしょう。
AIエージェントに強い会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 AIエージェントに強い会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
AIエージェントの品質と実用性を測定する6つの主要評価指標
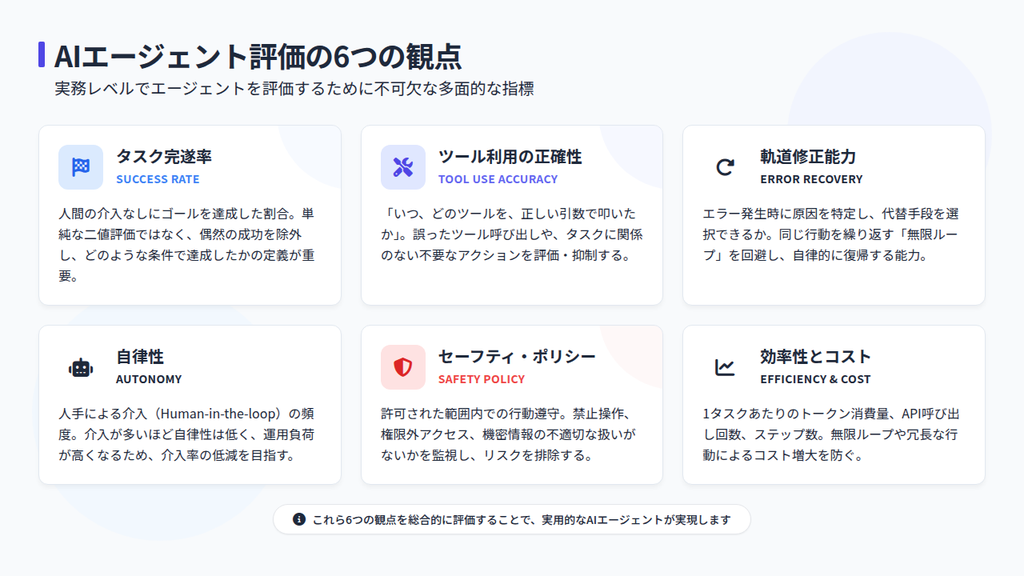
AIエージェントの評価を実務レベルで成立させるためには、以下の6つの観点が重要です。
関連記事:「AIエージェントの開発方法・手順を解説!必要な技術や代表的フレームワーク」
AIエージェントによる特定業務の完遂率(Success Rate)
タスク完遂率は、「メールを送る」「出張の手配をする」といったゴールに対し、何%が人間の介入なしに完了したかの割合です。ただし、AIエージェント評価における基本でありながら、定義が難しい指標です。
AIエージェントの場合、評価対象は単なる回答ではなく、タスク全体を完遂できたかという結果に置かれます。
AIエージェントは、複数ターンの対話や外部ツールの実行を通じてゴールに到達します。そのため、途中の判断や行動が遠回りであっても、最終的に目的が達成されていれば成功と見なされるケースがあります。
一方で、偶然ゴールに到達したように見えても、誤ったツール実行や不必要な試行錯誤を重ねている場合、それを成功として扱うことにはリスクが伴います。
このような特性から、AIエージェント評価におけるタスク完遂率は、単純な成功・失敗の二値では不十分です。どの条件を満たせば達成と見なすのか、制約違反があった場合に成功と判定してよいのか、といった基準を明確化する必要があります。
評価設計を曖昧にしたままでは、タスク完遂率そのものが形骸化し、実運用での信頼性を担保できません。
AIエージェントにおける外部ツール・API実行の正確性(Tool Use Accuracy)
エージェントが「いつ、どのツール(API)を、正しい引数で叩いたか」を評価します。AIエージェントは自律的に外部ツールやAPIを選択・実行できる一方で、その自由度の高さが誤動作の温床にもなります。
典型的な例として以下のようなケースが挙げられます。
- 本来参照すべきでないデータソースを呼び出す
- 権限外のAPIを実行しようとする
- タスク達成に直接関係のないツールを繰り返し試行する
最終的にゴールへ到達していたとしても、これらの行動はセキュリティリスクや運用負荷、コスト増大につながる可能性があります。
この種の問題が見逃されやすい理由は、評価が結果主義になりがちな点にあります。テキスト出力やゴール達成のみを評価対象とすると、途中でどのようなツール選択やアクションが行われたのかがブラックボックス化し、誤った実行や無駄な行動を検知できません。
そのためAIエージェント評価では、許可されたツールセットの範囲内で適切に実行されているか、不要なアクションが一定回数を超えていないかといった観点を評価指標として組み込む必要があります。
誤ったツール実行や不要なアクションを定量的に把握することで、AIエージェントの挙動を「安全かつ効率的に動いているか」という視点で評価できるようになるでしょう。
エラー発生時におけるAIエージェントの自己修復能力
エラーが発生した際、自ら原因を特定し、別の手段を講じたかどうかが重要な側面です。AIエージェントは自律的に判断と行動を繰り返すため、終了条件や進捗判定が適切に設計されていない場合、同じ思考やアクションを以下のように延々と繰り返してしまいます。
- ツール実行の結果を解釈できずに再試行を繰り返す
- 会話の文脈を更新できずに同一の質問を繰り返す
一見すると動いているように見えるため、ゴール未達のまま処理が長引いてしまう無限ループの原因になります。
無限ループが評価で検知されにくい理由として、従来のテストが一定のターンで終了することを前提としている点にあります。テスト実行がタイムアウトや強制終了で打ち切られると、その時点での挙動が失敗として記録されるだけで、なぜループに陥ったのかという分析が行われないまま放置されがちです。
人間の介入頻度(Human-in-the-loop Rate)に基づくAIエージェントの自律性
自律性は、AIエージェントが、人の指示や介入に依存せずにタスクを遂行できているかを測る評価観点です。ただタスクを完了できたかどうかではなく、その過程で人間の判断や修正がどれだけ必要だったのかを定量的に把握することが、AIエージェント評価では求められます。
実務では、この自律性を測る指標として、Human-in-the-loop Rateが用いられます。Human-in-the-loop Rateとは、タスク実行中に人間の介入が発生した頻度や割合を示すもので、介入回数が多いほどエージェントの自律性が低いことを意味します。
例えば、意思決定のたびに確認が必要なエージェントは、表面的には動作していても、業務の自動化という観点では十分と言えません。
自律性が低いAIエージェントは、運用負荷の増大やスケーラビリティの制約につながります。担当者が常に監視・修正を行う前提ではエージェントの導入効果は限定的になり、人手を置き換えられないシステムになってしまいます。
AIエージェント評価においては、Human-in-the-loop Rateをタスク完遂率と併せて評価することで、成功しているが人手が必要なエージェントと自律的に成功できるエージェントを明確に区別できます。
AIエージェントの動作におけるセキュリティ制約、セーフティ・ポリシーの遵守
セーフティ・ポリシーは、AIエージェントが許可された範囲内で行動しているかを評価するための観点です。AIエージェントは外部ツールやデータに自律的にアクセスできるため、誤った判断がそのまま情報漏えい・不正操作・法令や社内規定違反につながるリスクを内包しています。
特に問題となりやすいのは、以下のような点です。
- 禁止されたツールやエンドポイントへのアクセス
- 権限外操作の試行
- 機密情報や個人情報の不適切な取り扱い
これらはゴール達成の可否とは独立して発生するため、結果のみを評価していると見逃されがちです。タスクが成功していても、その過程でセーフティ・ポリシー違反が起きていれば、実運用では欠陥と判断されるでしょう。
AIエージェント評価では、セーフティ・ポリシーを例外的な処理ではなく、明確な評価指標として組み込むことが不可欠です。しかし、自社固有のコンプライアンスやセキュリティ基準をどのように評価ロジックへ落とし込むべきか、判断に迷うケースも少なくありません。
こうした課題に対し、AI Market(エーアイマーケット)では、安全性やガバナンスが重視されるエンタープライズ領域での導入実績が豊富な企業を厳選して紹介しています。
累計1,000件以上の相談に対応してきた専門のコンサルタントが、貴社の懸念事項をヒアリングした上で、リスク管理と性能評価を両立できる最適なパートナーを提案します。これにより、以下のような観点を継続的に監視できる体制をスムーズに構築することが可能になります。
AIエージェントの推論ステップ数とトークン消費量に基づく運用コスト効率
AIエージェントはマルチターンで推論と行動を繰り返すため、単発の生成AIと比べてトークン消費量やAPI呼び出し回数が大幅に増加しやすい特性があります。
無限ループや不要なアクションが発生している場合、ユーザーが気づかないままコストだけが積み上がるケースも珍しくありません。ゴールに到達しないまま処理が継続したり、同じ情報取得を何度も繰り返したりすると、品質面では問題が表面化しなくても運用コストは膨らみます。
この問題が見落とされやすい理由として、AIエージェント評価が性能評価とコスト評価に分断されがちな点にあります。テスト環境では成功しているように見えても、実運用スケールで同じ挙動が繰り返されると想定外の費用が発生することになります。
そのため、無限ループもタスク完遂率や品質指標と並行して、1タスクあたりのトークン消費量・ツール実行回数・推論ステップ数といったコスト指標を継続的に監視することが不可欠です。
AIエージェント評価におけるタスク完遂率の定義・判定基準の設定方法
AIエージェント評価においてタスク完遂率を有効な指標として機能させるには、何をもって成功とするのかを構造化して定義する必要があります。単純な成功・失敗では、マルチターン・非決定的に振る舞うAIエージェントを評価することはできません。
タスク進行状況を客観的に判定するための状態定義
AIエージェントのタスク完遂率を定義するためには、まず状態(State)を定義することが不可欠です。状態定義とは、エージェントがタスク実行の過程で、今どこまで進んでいるのか、何が完了し、何が未達なのかを判定できる基準を設けることを指します。
従来の生成AIは最終出力のみで評価が成立しましたが、AIエージェントでは途中経過が評価に直結します。そのため、初期状態・中間状態・ゴール状態といった段階を設定し、それぞれがどの条件を満たしていれば到達とみなすのかを定義する必要があります。
実務においては、状態をテキストではなく、構造化された条件として定義することが重要です。
- 必要な情報がすべて取得されているか
- 指定されたツール実行が完了しているか
- 禁止条件に抵触していないか
このように状態を定義することで、AIエージェントの挙動を、どの状態で停止・逸脱したのかという形で捉えられるようになります。
AIエージェントの実行結果を成功・部分成功・失敗の3段階に分類
AIエージェント評価においてタスク完遂率を機能させるためには、結果を成功・失敗の二値で判断しないことが重要です。AIエージェントが途中まで正しく進行していたにもかかわらず、最後の判断で失敗するケースや、主要な目的は達成しているが一部の条件を満たしていないケースはよくあります。
そこで有効なのが、ゴール達成を以下段階に分解する方法です。
- 成功:定義されたゴール状態とすべての制約条件を満たしている
- 部分成功:主要な目的は達成しているものの、補助的な条件や理想的な経路を満たしていない
- 失敗:ゴール状態に到達していない、もしくは重大な制約違反が発生している
この段階的な分解によって、なぜ失敗したのか、どこまで到達できていたのかを定量的に把握できるようになります。単なる失敗として扱うのではなく、部分成功として分類することでAIエージェントの能力向上や改善余地を具体的に分析できます。
AIエージェント評価では、このような段階的定義を前提にタスク完遂率を算出することで、実際の運用に近い形で性能を評価できます。
安全性・制約違反有無をタスク完遂判定の前提条件とする
タスク完遂率を定義する際に見落としてはならないのが、安全性や制約違反をどのように扱うかという視点です。AIエージェントは自律的に行動できるがゆえに、タスクを完了していても、その過程でポリシー違反や危険な判断を行っている可能性があります。
例えば以下のような判断・行動は、ゴール達成とは無関係に発生します。
- 禁止されたツールの使用
- 権限外データへのアクセス
- 想定外の外部通信
このような挙動を許容したまま成功と判定すると、形式上のタスク完遂率は高く見えても、実運用では利用できないエージェントを高く評価してしまうことになります。
そのため、安全性や制約違反をタスク完遂率の前提条件として設定しなければいけません。重大なポリシー違反が発生した場合は、ゴールに到達していたとしても失敗と判定する、あるいは部分成功の下限に位置づけるといったルールを設ける必要があります。
外部環境の固定化・モック化によるAIエージェント評価の再現性
AIエージェント評価における再現性とは、同じ条件でテストしたときに、同程度の結果が得られるかという観点です。タスク完遂率をKPIとして運用する以上、再現性が担保されていなければ、改善の効果測定やリリース判断が成立しません。
特にAIエージェントは、マルチターンでの判断と外部ツール連携を伴うため、生成AI以上に結果が揺れやすいという特性があります。
再現性を難しくする要因は大きく分けて2つです。
- モデルの非決定性:温度設定やサンプリングにより、同一入力でも経路や出力が変化し得る
- 外部環境の変動:検索結果、API応答、データベースの更新、ネットワーク遅延などが、AIエージェントの行動選択を変える
結果として、たまたま成功した、偶然失敗したといった事象が混入し、タスク完遂率が指標として不安定になります。
再現性を確実に評価するには、再現性を前提にテスト条件を固定化する設計が必要です。以下のような手段により、評価対象をAIエージェントのロジックと振る舞いに寄せることが可能です。
- 評価用のツール実行結果をモック化する
- 取得データのスナップショットを用意する
- 最大ターン数やタイムアウトを統一する
- モデル設定(温度など)を固定する
完全な再現性が難しい場合は、単発結果で判定しない設計が有効です。複数回実行して成功率の分布として捉える、一定の信頼区間で評価する、といった形で、揺らぎを前提にタスク完遂率を解釈します。
AIエージェントに強い会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 AIエージェントに強い会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
AIエージェント評価の代表的な評価フレームワーク6選
AIエージェント評価を体系的に行うには、個別に指標を設計するだけでなく、既存の評価フレームワークを理解しておくことが有効です。以下では、AIエージェント評価の文脈で参照されることの代表的な以下評価フレームワークを6つ紹介します。
| フレームワーク | 評価の主眼 | 向いている業界・用途 |
|---|---|---|
| GAIA | 汎用的・実務的推論 | 一般事務・アシスタント業務 |
| SWE-bench | コード修正・テスト通過 | ソフトウェア開発・保守 |
| AgentBench | 多面的な地頭の良さ | 複雑な意思決定・データ処理 |
| AutoGenBench | エージェント間の連携 | 複数部門を跨ぐ複雑なワークフロー |
| WebArena | ブラウザ・UI操作 | BPO・EC・Webサービス運用 |
| ALFWorld | 手順・行動計画 | ロボティクス・物流・設備管理 |
それぞれのフレームワークについて詳しく説明します
汎用アシスタントの実務能力を評価するGAIA(General AI Assistants)
Meta AIやHugging Faceのチームなどによって提唱されたGAIA(General AI Assistants)は、汎用的なAIアシスタントの実用能力を測定することを目的とした評価フレームワークです。複数ステップの推論や外部情報の活用を前提としたタスクを通じて、AIエージェントとしての総合的な遂行能力を評価します。
GAIAの特徴は、タスクが実務に近い形で設計されている点にあります。以下のプロセスを一連の流れとして捉え、途中でどのような判断や行動が行われたかも評価対象に含まれます。
- 情報収集
- 推論
- 整理
- 最終的なアウトプット
そのため、知識量や言語能力だけでなく、ゴールに向かって適切な手順を選択できているかが問われます。
GAIAは、タスク完遂率との親和性が高いフレームワークといえます。最終的にタスクが完了しているかどうかに加え、途中で致命的な誤判断や行き詰まりが発生していないかを確認できるため、エージェントの実用性を俯瞰的に把握できます。
ソフトウェア開発能力を評価するSWE-bench
SWE-benchは、ソフトウェア開発タスクにおけるAIエージェントの実行能力を評価するベンチマークです。主に、実在するOSSリポジトリ上のバグ修正を対象とし、問題の理解から修正実装、テスト通過までを一連のタスクとして評価します。
SWE-benchの特徴は、評価が明確に決定論的である点にあります。
AIエージェントが生成したコード変更が、既存のテストスイートをすべて通過するかどうかによって成功・失敗が判定されます。そのため、動作するかどうかが客観的に評価でき、タスク完遂率を厳密に定義しやすいフレームワークといえるでしょう。
一方で、これはAIエージェント評価における限界も示しています。SWE-benchでは、ゴールが明確で制約条件も厳密に定義されているため、現実の業務エージェントのような曖昧さや分岐の多いタスクは扱いにくい側面があります。
とはいえ、SWE-benchは、エージェントが複数のステップを通じて確実にゴールへ到達できるかを検証するうえで非常に有用です。
多面的な実行能力を横断的に測定するAgentBench
AgentBenchは、AIエージェントの実行能力を横断的に評価することを目的としたフレームワークです。以下のトータルタスクを通じて、エージェントとしての総合的な振る舞いを評価します。
- 質問応答
- 推論
- ツール利用
- 環境操作
- 各ステップの意思決定
AgentBenchの特徴は、タスク領域の幅広さにあります。
Web操作、データ処理、推論タスクなど、異なる性質の課題が用意されており、単一指標では測れないAIエージェントの能力を多面的に比較できます。これにより、特定タスクには強いが、汎用的なエージェントとしては弱いといった特性も可視化されます。
評価手法の観点では、AgentBenchはタスク完遂率を中心としつつ、途中の行動やツール選択の妥当性も重視します。そのため、どのような経路でゴールに到達したかを分析できる点がAIエージェント評価との親和性を高めています。
マルチエージェント環境での協調動作を検証するAutoGenBench
AutoGenBenchは、マルチエージェント環境におけるAIエージェントの協調的な振る舞いを評価するフレームワークです。単一エージェントの能力ではなく、複数のエージェントが役割分担しながらタスクを遂行できるかという点に焦点を当てています。
このフレームワークでは、以下のようなプロセスが評価対象になります。
- エージェント同士の対話
- タスク分解
- 情報共有
最終的なゴール達成だけでなく、適切に役割が割り当てられているか、不要なやり取りが発生していないかといった点も重要視されます。そのため、AutoGenBenchはAIエージェント設計の妥当性を検証する用途に向いています。
AIエージェント評価の観点からみると、AutoGenBenchはタスク完遂率とプロセス評価を組み合わせた例として参考になるでしょう。複数のエージェントが関与することで、誤った判断が連鎖したり、責任の所在が曖昧になるといった問題も顕在化しやすく、失敗分析の視点を提供してくれます。
Web環境におけるブラウザ操作と探索行動を評価するWebArena
WebArenaは、AIエージェントが実際のWeb環境を操作しながらタスクを達成できるかを評価する定番のフレームワークです。人間がブラウザ上で行う以下のような操作をエージェントに実行させ、達成度を測定します。
- 検索
- フォーム入力
- ページ遷移
- 情報抽出
このフレームワークの特徴として、評価対象が高度に非決定的である点にあります。単純なルールベースのテストでは対応できないため、WebArenaでは最終的なタスク完了の可否を中心に、エージェントが状況を理解し、行動を選択できているかが評価されます。
AIエージェント評価の観点では、WebArenaは現実環境に近い評価を行える点で価値があるといえるでしょう。
UI操作や探索行動が求められるため、誤操作、無限ループ、不要なアクションといった問題が顕在化しやすく、失敗分析にも適しています。
仮想環境での指示理解と行動計画を評価するALFWorld
ALFWorldは、AIエージェントが仮想環境内で指示理解から行動計画、実行までを一貫して行えるかを評価するフレームワークです。物を探す・移動する・操作するといった一連の行動を自然言語指示に基づいて遂行できるかが評価されます。
ALFWorldの特徴は、言語理解と行動計画が密接に結びついている点にあります。
指示理解にとどまらず、どの順序で行動すべきか、失敗した場合にどうリカバリするかといった判断が求められます。そのため、長期的なゴール追従能力や無限ループに陥らずに完遂できるかといった観点を検証しやすいです。
また、ALFWorldはシミュレーション環境であるため、状態や結果を定義でき、タスク完遂率を安定して算出できます。これは、非決定性の高い実環境評価と対照的であり、AIエージェントの基礎能力を切り分けて評価するうえで有用です。
AIエージェントの挙動観測および品質管理を支援する主要ツール6選
AIエージェント評価を実務に落とし込むうえでは、フレームワークだけでなく、評価を実行・可視化するためのツールの活用が欠かせません。以下では、AIエージェントの挙動観測、評価、失敗分析を可能にする評価ツールを6つ紹介します。
| ツール名 | 提供形態 | 評価の自動化 (LLM-as-a-judge) | コスト・性能 観測能力 | セキュリティ・ 柔軟性 | 特徴・おすすめの企業 |
|---|---|---|---|---|---|
| Maxim AI | クラウド (SaaS) | ◎ 強力 | ◎ | ◯ | 【評価の自動化を最優先】 評価ルールをテンプレート化し、チームで改善サイクルを回したい企業に最適。 |
| Langfuse | OSS / クラウド | △ (拡張可能) | ◯ | ◎ | 【挙動の透明性と安全性を重視】 自社サーバー(セルフホスト)が可能。ログ追跡とデバッグに強く、機密情報を扱う企業向け。 |
| Arize Phoenix | OSS | ◯ | ◯ | ◎ | 【モデル品質の深掘り】 データサイエンス的な視点で、応答の一貫性やドリフトを詳細に分析したい技術者主導のチーム向け。 |
| Helicone | クラウド / OSS | △ | ◎ 強力 | ◯ | 【運用コストの最適化】 複数エージェントのAPI消費やレイテンシを可視化し、ビジネスROIを厳密に管理したい企業向け。 |
| OpenPipe | クラウド | ◯ | △ | ◯ | 【評価を学習に繋げたい】 評価結果をもとにファインチューニングを行い、自社専用モデルへ昇華させたい開発チーム向け。 |
| TruLens | OSS | ◎ 強力 | △ | ◯ | 【理論的な妥当性評価】 「根拠性」や「指示遵守」など、独自の評価関数(Feedback Functions)を厳密に組みたい企業向け。 |
それぞれのツールについて説明します。
LLM-as-a-judgeによる自動評価を支援するMaxim AI
Maxim AIは、生成AIおよびAIエージェントの評価・観測・改善を一体で扱うことを目的とした評価ツールです。マルチターンで動作するAIエージェントに対して、振る舞いを測定・分析できます。
Maxim AIでは、以下の要素を横断的に可視化できます。
- タスク完遂率
- 品質評価
- ツール実行ログ
- トークン消費量
- レイテンシ
これにより、なぜ成功したのか、どこで失敗したのかといった分析を、会話やアクションの履歴に基づいて行うことが可能です。AIエージェント評価を結果だけでなく、プロセス単位で分解して確認できる点が実務向きといえます。
AIエージェントの評価において、ログはもはや単なるデバッグ用ではありません。万が一の事故の際、『なぜその判断を下したのか』という証拠を残すためのブラックボックス(飛行記録装置)として必要不可欠なのです。
また、LLM-as-a-judgeによる評価設計や評価ルールのテンプレート化にも対応しており、属人的になりがちな評価をチーム全体で共有しやすくなります。これにより、AIエージェント評価を継続的な改善サイクルとして回すことができます。
マルチターンの挙動追跡とデバッグに特化したLangfuse
Langfuseは、AIエージェントの挙動観測と評価を行うためのオープンソースツールです。マルチターンの会話やツール実行を伴うエージェントのログを一貫して追跡できます。
Langfuseでは、プロンプトやモデル応答といった情報を時系列で可視化できます。そのため、AIエージェントがどの判断の結果として現在の状態に至ったのかを把握しやすく、失敗分析やデバッグを効率的に行えるようになります。
AIエージェント評価の観点からみると、Langfuseはタスク完遂率そのものを算出するというよりも、その前提となる行動ログの取得・分析を担うツールと位置づけられます。誤ったツール実行や無限ループ、不要なアクションの兆候をログから発見し、評価設計やテストケース改善につなげる用途に適しています。
また、セルフホストが可能である点も特徴で、機密データを扱う業務エージェントでも導入しやすく、評価基盤を自社環境に組み込みたい場合におすすめです。Maxim AIのようなクラウド型は導入が迅速ですが、Langfuseのようなセルフホスト可能なOSSの選択も検討すべき重要なポイントです。
応答の一貫性、ドリフト分析を行うArize Phoenix
Arize Phoenixは、LLMやAIエージェントの品質評価と挙動分析に特化したオープンソースの評価ツールです。もともとはモデル評価やデータドリフト検知の文脈で使われてきましたが、近年はAIエージェント評価への活用も進んでいます。
Arize Phoenixの特徴は、LLM-as-a-judgeを用いた評価設計や、出力品質を多角的に可視化できる点にあります。ゴール達成の成否だけでなく、応答の一貫性や妥当性といった観点を定量化できるため、定性的になりがちな評価を構造化することが可能です。
AIエージェント評価の文脈では、Phoenixはマルチターン会話の全体を対象とした品質分析ができます。どのターンで品質が劣化したのか、どの判断が失敗につながったのかを追跡しやすく、失敗原因の特定に役立ちます。
AIエージェントのAPI利用状況、コスト消費を可視化するHelicone
Heliconeは、AIエージェントのAPI利用状況を可視化・分析するための評価ツールです。大規模言語モデル(LLM)の呼び出し回数やトークン消費量、レイテンシといった運用指標を詳細に把握できるのが特徴です。
AIエージェント評価においては、Heliconeは品質そのものを直接評価するツールというよりも、コストと挙動の実態を観測するための基盤として機能します。マルチターンで推論とツール実行を繰り返すAIエージェントでは、どの判断がコスト増大につながっているのかを追跡することが重要であり、Heliconeはその可視化を得意とします。
また、リクエスト単位・ユーザー単位・シナリオ単位での分析が可能なため、特定のテストケースや失敗パターンにおけるコスト異常を発見しやすくなります。これは、タスク完遂率だけでは捉えられない運用上の失敗を評価に組み込むうえで有効です。
さらに、Heliconeは他の評価・分析ツールと組み合わせることで、品質・行動・コストを横断的に捉えるAIエージェント評価基盤を構築しやすくなります。
実運用ログをモデル改善に反映させるOpenPipe
OpenPipeは、AIエージェントの出力品質を改善・評価することを目的としたプラットフォームです。ログ収集から評価、モデルの改善までを一連のワークフローとして扱えます。
AIエージェント評価の文脈からみると、OpenPipeはタスク完遂率や品質評価の結果をもとに、どの挙動を改善すべきかを明確にする役割を担います。実運用のログから成功・失敗パターンを分析することで、AIエージェントの振る舞いをデータドリブンに改善できます。
また、主観的になりがちな評価基準を段階的に標準化しやすくなるため、AIエージェント評価を属人的なレビューから、再現性のある工程へと移行させるうえで有効です。OpenPipeは評価ツールというよりも、評価結果を次の改善につなげるための基盤と位置付けられるでしょう。
評価関数を用いてAIエージェントの妥当性をスコアリングするTruLens
TruLensは、AIエージェントの振る舞いを定量的に評価するオープンソースツールです。LLM-as-a-judgeを活用した自動評価に強みを持ち、品質や妥当性を複数の観点から測定することが可能です。
TruLensでは、以下のような評価指標を柔軟に定義でき、マルチターンの会話全体を対象にスコアリングすることが可能です。
- 回答の一貫性
- 根拠性
- 指示遵守
これにより、AIエージェントが「一見それらしいが本質的に誤っている」挙動をしていないかを検出しやすくなります。
AIエージェント評価の文脈において、TruLensはゴール達成の質を測る補助的な指標として機能します。タスクは完了していても、判断や説明の妥当性に問題があるケースを可視化できます。
AIエージェントに強い会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 AIエージェントに強い会社選定を依頼
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
AIエージェント評価を組織的な開発プロセスとして標準化する5つの工程
AIエージェント評価を実務で運用するためには、単発の検証作業ではなく、開発プロセスに組み込まれた工程として設計することが重要です。評価観点や指標が整理されていても、実行方法が属人的であれば、再現性や改善速度は担保できません。
以下では、AIエージェント評価を標準化するするために有効な5つの工程を解説します。
シナリオ脚本に基づくマルチターンテストを定常的に実行
AIエージェント評価を標準化するうえで取り組むべき工程が、マルチターンテストを定常的に実行する仕組みの背t系です。単発の検証では、エージェント特有の分岐や長期的な挙動を捉えることはできません。
マルチターンテストでは、会話や行動の流れを脚本として定義し、挙動をまとめて検証します。これにより、途中での誤判断・不要なアクション・無限ループの兆候などを流れとして観測できます。
定常実行を前提にすることで、モデル更新やプロンプト変更が、AIエージェントの振る舞いにどのような影響を与えたのかを定量的に比較できます。マルチターンテストを常に回し続けることで、再現性のある評価工程へと変えていくことでしょう。
トークン消費量、リソース制約をAIエージェントの評価項目に組み込む
AIエージェントはマルチターンで推論と行動を繰り返すため、性能が向上するほどコストが増大する傾向があります。そのため、品質やタスク完遂率と並行して、コストおよびリソース制約を評価に組み込むことが不可欠です。
評価工程では、以下のような指標に上限や許容範囲を設定します。
- 1タスクあたりのトークン消費量
- ツール実行回数
- 推論ステップ数
- 処理時間
これにより、動作は正しいが使えないAIエージェントを早期に検出できるようになります。コストを後工程で確認するのではなく、評価段階で制約として扱うことが重要なのです。
コストとリソースの制約を評価に組み込むことで、AIエージェントが事業として持続可能かという観点でも判断できるようになります。
時間経過に伴うタスク完遂率の推移を定量的・継続的に測定
AIエージェント評価を工程として成立させるには、タスク完遂率を一度きりの指標として扱わず、継続的に測定することが重要です。単発のテスト結果では、モデル更新や環境変化による性能の揺らぎを捉えることはできません。
継続的な測定では、同一のテストシナリオを定期的に実行し、成功率・部分成功率・失敗率の推移を追跡します。これにより、AIエージェントの性能が安定しているのか、改善しているのか、あるいは劣化しているのかを定量的に判断できます。
また、タスク完遂率を時系列で可視化することで、品質評価と他指標との関係性も把握しやすくなります。コスト増加と成功率向上のトレードオフや、安全制約の強化による影響なども分析できるようになります。
AIエージェント評価をCI/CDパイプラインへ統合し自動検証
AIエージェント評価において、CI/CDパイプラインへの統合も重要です。評価が人手による確認に依存している限り、判断は属人的になり、品質のばらつきを防げません。
CI/CDへの統合では、コード変更、プロンプト更新、モデル差し替えのタイミングで、自動的にマルチターンテストやタスク完遂率の測定を実行します。これにより、変更がAIエージェントの振る舞いに与える影響を把握でき、想定外の劣化やリスクを早期に検知できふようになります。
失敗分析、意思決定を支援するテストサマリーの可視化
AIエージェント評価を工程として定着させるには、テスト結果を「実行した」で終わらせず、テストサマリーとして可視化し、同じ基準で判断できる状態を作ることが重要です。評価がブラックボックスのままでは、改善の優先順位付けも、リリース可否の判断も属人的になるでしょう。
可視化のポイントとしては、タスク完遂率のような集計指標だけでなく、失敗の内訳を明確に示すことが挙げられます。例えば、以下の要素を同一画面で確認できれば、なぜ評価が低いのか、どこが危険なのかを短時間で把握できます。
- 成功・部分成功・失敗の比率
- 誤ツール実行の発生数
- 無限ループ検知回数
- セーフティ・ポリシー違反件数
- コスト上限超過の頻度
このような評価プロセスの標準化や、適切な評価ツールの選定を自社のみで完結させるのが難しい場合は、プロの知見を借りるのが近道です。
AI Marketをご活用いただければ、AI特化のコンシェルジュが貴社の要件を整理し、100社を超える審査済み企業の中から、評価基盤の構築に強みを持つ数社を1〜3営業日以内に無料で紹介いたします。
一括見積もり型のような大量の電話に悩まされることなく、満足度96.8%の高品質なマッチングを通じて、信頼性の高いAIエージェント運用への第一歩を迅速に踏み出すことができます。
AIエージェントの評価についてよくある質問まとめ
- AIエージェントの評価に生成AIの評価が通用しない理由は?
生成AIの評価は、主に単一入力に対する出力の品質を測ることを前提としています。一方、AIエージェントはマルチターンで会話や行動を繰り返し、途中で経路が分岐しながらタスクを遂行します。
そのため、最終出力だけを見ても、誤ったツール実行や無限ループ、危険な判断といった問題を検知することはできません。
- AIエージェントの評価に有効な指標は?
AIエージェント評価では、複数の観点を組み合わせて評価することが重要です。代表的な指標には以下があります。
- タスク完遂率(成功・部分成功・失敗の段階的定義)
- 誤ったツール実行や不要なアクションの発生頻度
- 無限ループや停滞状態への陥りやすさ
- 自律性(Human-in-the-loop Rate)
- セーフティ・ポリシー違反の有無
- トークン消費量やAPI呼び出し回数などのコスト指標
- AIエージェントの評価に活用できるフレームワークは?
AIエージェント評価では、研究・実務の両面で利用されている以下のフレームワークが参考になります。
- GAIA
- SWE-bench
- AgentBench
- AutoGenBench
- WebArena
- ALFWorld
- 自社でAIエージェントを開発中ですが、どの評価ツールを導入すべきか判断がつきません。
求める目的が「デバッグとログ追跡」ならLangfuse、「自動スコアリング」ならMaxim AIやTruLens、「コスト管理」ならHeliconeといった使い分けが必要です。AI Marketでは、貴社の開発フェーズやセキュリティ要件、予算に合わせ、最適なツールの選定支援や、それらを使いこなせる実績豊富な開発会社を無料でご紹介可能です。
- 評価環境の構築(モック化やCI/CD統合)には高度なエンジニアリングが必要に見えますが、外注は可能ですか?
はい、可能です。AIエージェントの評価基盤構築は、単なる開発以上に専門的なノウハウが求められます。AI Marketのコンシェルジュにご相談いただければ、単に「作る」だけでなく、評価パイプラインの構築やLLM-as-a-judgeの実装に長けた、審査済みの優良AI開発企業を厳選して接続いたします。
まとめ
AIエージェントの評価は、従来の生成AI評価の延長では成立しません。マルチターンで分岐し、外部ツールを自律的に実行するAIエージェントに対しては、正しい答えを出したかどうかという視点だけでは不十分であり、どのような過程でゴールに到達したのか、あるいは到達できなかったのかを評価する設計が求められます。
本記事でも示したように、AIエージェント評価の本質は、タスク完遂率を中心に据えながらも、誤ツール実行、無限ループ、自律性、安全性、コストといった複数の観点を扱うことにあります。これらは個別に測る指標ではなく、相互に影響し合う品質要素であるため、どれか一つを無視した評価は、実運用で破綻します。
非決定的な挙動を示すエージェントの評価環境をゼロから設計し、適切なツールを選定して運用に乗せるには、最新の技術トレンドと実務経験の双方が求められます。
自社に最適な評価フレームワークの構築や、信頼できる開発パートナーの選定において、より深い知見や具体的なアドバイスが必要な場合は専門のコンサルタントによる支援を受けることも検討してください。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

