
LINEヤフー、高性能日本語マルチモーダルモデル「clip-japanese-base-v2」を商用可能ライセンスで公開
最終更新日:2025年12月23日
記事監修者:AI Market ニュース配信チーム
LINEヤフーは2025年12月18日、画像と言語を扱う日本語マルチモーダル基盤モデル「clip-japanese-base-v2」を公開した。
前バージョンから学習データと学習方法を大幅に改善し、パラメータ数196Mと最小クラスながら既存の日本語特化モデルやマルチリンガルモデルを上回る性能を実現した。
- Common Crawlから収集した5.4億件の高品質な画像・テキストペアデータで学習し、従来の10億件から28億件にデータ規模を拡大
- negCLIPLossによるフィルタリングと知識蒸留技術を採用し、ゼロショット画像分類や画像・テキスト検索で高精度を達成
- パラメータ数196Mで他の日本語CLIPモデルやGoogleのSigLIPモデルより優れた性能を示し、商用利用が可能
clip-japanese-base-v2は、Common Crawlの2020年から2025年までの6年分39スナップショットを対象に画像URLを抽出し、フィルタリング前の画像サンプル数を前バージョンの10億件から28億件に増加させた。最終的に5.4億件の高品質な画像・テキストペアを学習データとして使用している。
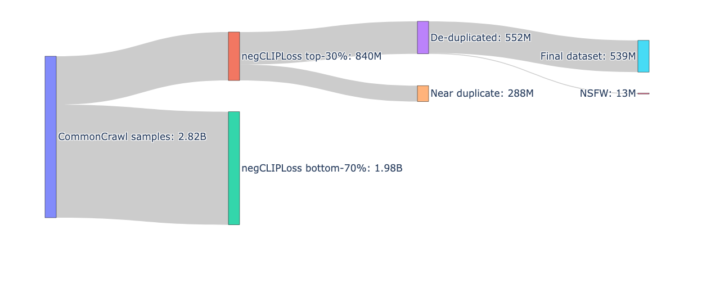
データの質を高めるため、従来のCLIP-scoreに代わりnegCLIPLossという新しい指標を採用した。この指標は、シンプルな画像やテキストで類似度が高くなりやすいというCLIP-scoreのバイアスを排除するため、サンプル自身の性質を考慮した正規化項を含んでいる。
さらに、Data Filtering Networksの研究知見に基づき、人間が付けたキャプションを持つクリーンなデータのみで学習したフィルタリング専用のCLIPモデルを構築した。
内部実験では、ダウンストリームタスクの精度が高いモデルが必ずしもデータフィルタリングに適しているわけではないことが確認されている。
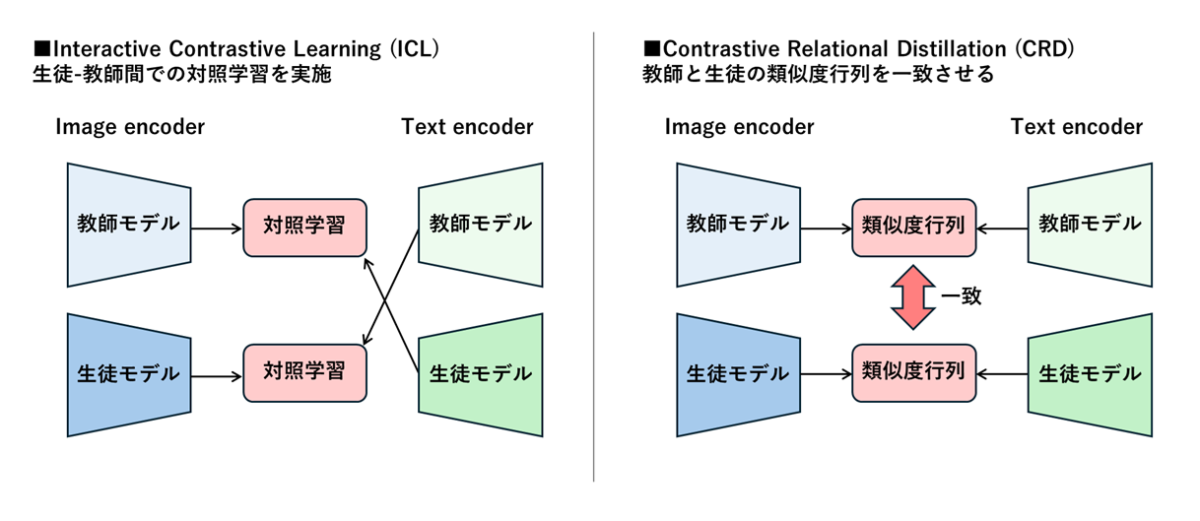
clip-japanese-base-v2では、学習データの更新に加えて知識蒸留による高精度化にも取り組んだ。知識蒸留は大規模で高精度な教師モデルの知識を小さな生徒モデルに受け渡す手法だ。
CLIP-KDという先行研究を参考に、Interactive Contrastive Learning(ICL)とContrastive Relational Distillation(CRD)の組み合わせを採用した。ICLは教師モデルと生徒モデルの特徴量を用いた対照学習によって生徒側の表現を強化する手法で、CRDは両モデルで計算した画像とテキストの類似度を一致させるように学習させる。
特にCRDは画像とテキストの類似度計算という実際のユースケースに即した方法となっており、LINEヤフーのチームは独自の改良を加えることで大幅な精度改善に成功した。教師モデルにはvision encoderとしてsiglip2-so400m-patch14-224を採用し、日本語データでCLIPを学習させている。
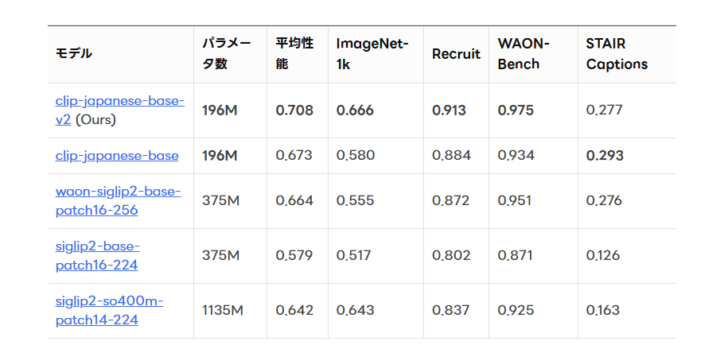
性能評価では、日本語ImageNet-1k、Recruitの評価データセット、WAON-Bench、STAIR Captionsの4つのデータセットを使用した。clip-japanese-base-v2はパラメータ数196Mと最も少ないにもかかわらず、平均性能0.708を達成し、前バージョンの0.673、waon-siglip2-base-patch16-256の0.664、Googleのsiglip2-so400m-patch14-224の0.642を上回った。
学習データ更新により平均性能が0.673から0.680に向上し、知識蒸留の追加でさらに0.708まで改善した。ImageNet-1kでは0.666、Recruitデータセットでは0.913、WAON-Benchでは0.975という高い精度を示している。
モデルはApache-2.0ライセンスで公開されており、商用利用が可能だ。LINEヤフーではYahoo!オークションの出品審査効率化やYahoo!フリマの類似画像検索など、実サービスでCLIPを活用している。
AI Market の見解
clip-japanese-base-v2は、日本語に特化したマルチモーダルAIモデルの実用性を大きく高める成果だ。技術的には、negCLIPLossによるバイアス除去とクリーンデータで学習したフィルタリング専用モデルの構築により、データ品質の向上を実現している点が注目される。
知識蒸留においてCRDに独自改良を加えた点も、実用的なユースケースに即した最適化として評価できる。ビジネス的には、パラメータ数196Mという軽量性を保ちながら大規模モデルを上回る性能を達成したことで、導入コストと運用効率の両面で優位性を持つ。
Apache-2.0ライセンスでの公開は、日本語マルチモーダルAIの普及を加速させると想定される。LINEヤフーが自社サービスで実際に活用している実績は、モデルの信頼性を裏付けるものだ。
今後、ECサイトの商品検索、コンテンツモデレーション、画像分類など、日本語環境における視覚-言語タスクの精度向上に広く貢献すると想定される。
参照元:LINEヤフー株式会社
clip-japanese-base-v2に関するよくある質問まとめ
- clip-japanese-base-v2は前バージョンと比べてどのような点が改善されたのか?
主に学習データと学習方法の2点が改善された。学習データ面では、Common Crawlのデータ規模を10億件から28億件に拡大し、negCLIPLossという新しい指標でバイアスを除去したフィルタリングを実施した。学習方法面では、知識蒸留技術を導入し、ICLとCRDの組み合わせにより小さなモデルサイズで高性能を実現している。これらの改善により、平均性能が0.673から0.708に向上した。
- clip-japanese-base-v2はどのような用途で利用できるのか?
ゼロショット画像分類や画像・テキスト検索など、画像と言語を組み合わせたタスクに利用できる。LINEヤフーではYahoo!オークションの出品審査効率化やYahoo!フリマの類似画像検索に活用している。Apache-2.0ライセンスで公開されているため、商用利用も可能で、ECサイトの商品検索、コンテンツモデレーション、画像分類など幅広い応用が期待される。

AI Market ニュース配信チームでは、AI Market がピックアップするAIや生成AIに関する業務提携、新技術発表など、編集部厳選のニュースコンテンツを配信しています。AIに関する最新の情報を収集したい方は、ぜひ𝕏(旧:Twitter)やYoutubeなど、他SNSアカウントもフォローしてください!
𝕏:@AIMarket_jp
Youtube:@aimarket_channel
TikTok:@aimarket_jp
過去のニュース一覧:ニュース一覧
ニュース記事について:ニュース記事制作方針
運営会社:BizTech株式会社
ニュース掲載に関するご意見・ご相談はこちら:ai-market-press@biz-t.jp

