
LlamaIndexとは?RAGの構築を実現するライブラリの機能やメリット、構築手順を徹底解説!
最終更新日:2025年08月21日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

社内データを参照にした回答生成を可能にするRAGは、LLM(大規模言語モデル)を企業で活用するために欠かせない方法となっています。しかし、社内データを生成AIと統合させるには、開発工数やコストがかかるため、RAGの開発はハードルが高いと感じる方もいるでしょう。
RAGとはなにか、機能や仕組みをこちらの記事で、LLMについてはこちらで詳しく説明していますので併せてご覧ください。
そこで有効なのが、LlamaIndexです。LlamaIndexはPythonのライブラリで、RAGの構築に最適なツールとして活用されています。
この記事では、LlamaIndexの概要から特徴、メリット、RAGの構築手順について解説していきます。自社用のRAGを開発したいと考えている方は、ぜひ参考にしてみてください。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!

・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
ChatGPT/LLM導入・カスタマイズに強いAI開発会社を自力で選びたい方はこちらで特集していますので併せてご覧ください。
目次
LlamaIndexとは?

LlamaIndexは、LLM(大規模言語モデル)の開発に活用されるオープンソースのPythonライブラリです。様々なデータソースからデータを読み込み、読み込んだデータの管理と活用を効率化するためのアプローチを提供し、LLMで扱いやすい形にしてくれます。
一般的なLLMでは、ユーザーの独自データを直接活用するには限界があります。LlamaIndexは、LLMが以下の機能を持ち、データに直接アクセスして高度な応答を生成するのを支援します。
- データの取り込みと構造化
様々なデータソース(テキストファイル、PDF、Webサイト、データベース、APIなど)からデータを読み込み、LLMが利用しやすい形に構造化します。 - インデックス作成
取り込んだデータをクエリ可能なデータ構造「インデックス」に変換します。これにより、効率的なデータ検索が可能になります。 - クエリ処理
作成したインデックスを用いて、ユーザーの質問に関連する情報を効率的に検索し、LLMに提供します。
LlamaIndexによるフレームワークは、情報検索システムやレコメンデーションエンジンのようなアプリケーションを構築する際に活用することが可能です。これにより、独自データを活用したモデルの設計が手軽になります。
LlamaIndexは、プリンストン大学でコンピューターサイエンスの学士号を取得し、Uberの元リサーチサイエンティストであるJerry Liuによって開発されました。名称にLlamaは入っていますが、Meta社のLLMであるLlamaとの直接的な関係はありません。同じくオープンソースのLLMプロジェクトであるLlamaへのリスペクトを込めて命名されたようです。
LangChainとの違い
LLMを活用したアプリケーションの開発をサポートする手法として、LangChainというフレームワークもあります。LlamaIndexはLangChainの競合というよりも、異なる強みを持つ補完的なツールと見なすことができます。
LangChainは、主にLLMを使用した複雑なタスクのワークフロー設計や、APIやデータソースとの連携を中心に据えたより汎用的なツールです。
異なるLLMの組み合わせや、外部ツールを統合したプロセス全体を管理する機能として、LangChainは優れています。一方で、データのインデックス化や検索精度の向上といった特定のニーズに対するサポートは、LlamaIndexほど特化していません。
一方のLlamaIndexは、既存データの取り扱いに強く、構造化データや非構造化データを効率的にインデックス化し、LLMと統合します。
また、LlamaIndexは検索精度やデータの利用効率を最大化する仕組みにフォーカスしています。そのため、RAG(検索拡張生成)の開発や特定用途向けのアプリケーション構築において、最適なアプローチを提供することが可能です。
LangChainは多目的で高度なワークフローを構築したい場合に適しており、LlamaIndexは特定データを活用してLLMの能力を引き出したい場合に最適な手法と言えます。多くの場合、LlamaIndexとLangChainを組み合わせることで、データ管理とAI処理能力の強力な組み合わせを実現できます。
関連記事:「LangChainとは?メリット・機能・始め方・活用事例・他LLMフレームワークとの比較徹底解説!」
LlamaIndexの料金
LlamaIndexはオープンソースのPythonライブラリであるため、無料で利用することが可能です。
ただし、LlamaIndexを活用する際には、バックエンドとしてLLMや埋め込みモデルを使用するのが一般的です。これらのモデルを利用する際には、各サービスプロバイダーが定めるAPI使用料が発生します。
例えばOpenAIのAPIを使用する場合、入力プロンプトと生成される出力のトークン数に応じて料金が課金されます。
関連記事:「ChatGPTのAPI料金詳細!各プランコスト比較・支払方法・料金節約手法!」
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
LlamaIndexの特徴
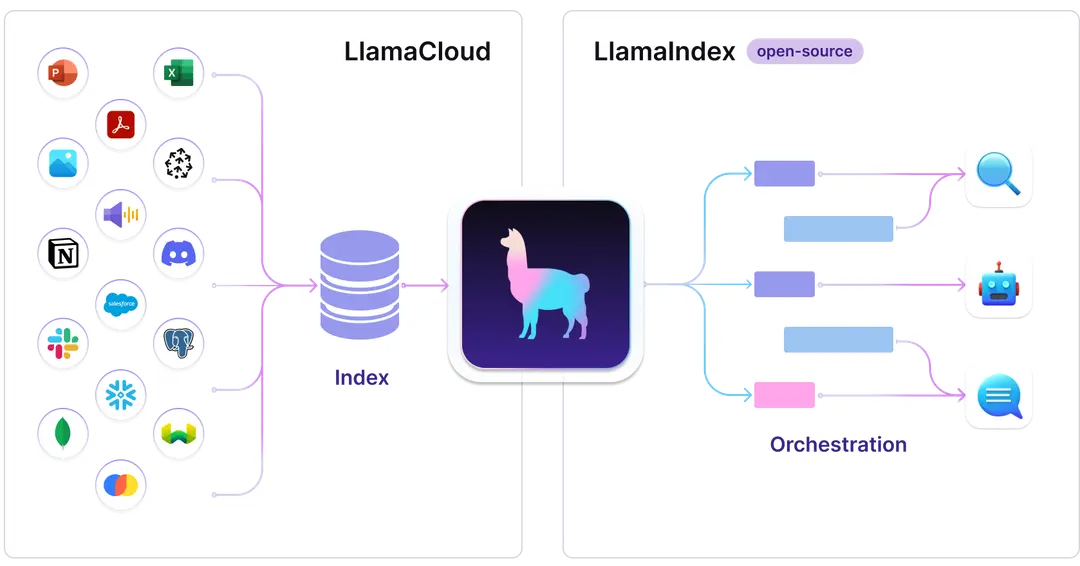
LlamaIndexの強みは、データのインデックス化から検索、拡張性まで幅広く対応できる点にあります。以下では、具体的な特徴について詳しく解説していきます。
既存データの読み込みとインデックス化に特化
LlamaIndexは、既存データの取り込みとインデックス化において優れた機能を提供します。スケーラビリティを考慮した設計がなされており、膨大なデータセットに対して高い処理能力を発揮します。
これにより、企業内の分散データや過去のアーカイブデータを含む多様なデータを読み込み、検索可能なインデックスとして構築することが可能です。
多様なデータソースに適用する
LlamaIndexは多様なデータ形式にも対応し、それらをLLMが利用可能な形に変換します。
具体的には、構造化データ(SQLデータベース、CSVファイル)や非構造化データ(PDF、Word文書、Webページ)に対応することが可能です。さらに、クラウドストレージやAPI経由でアクセスするデータ、さらにはリアルタイムで生成されるデータにも柔軟に適応可能です。
加えて、データソースが多岐にわたる場合でも、LlamaIndexの統合プロセスはシンプルであるため、直感的な設定によって短期間での適用が可能です。
高い拡張性
LlamaIndexは非常に高い拡張性を備えており、多様なニーズに応じて機能をカスタマイズできます。大規模なデータセットや複雑なシステム環境においてもスムーズに適応し、効果的に運用できる仕組みとなっています。
LlamaIndexはモジュール化された構造を採用しており、特定の機能を追加・変更する際に既存のシステム全体を再構築する必要がありません。また、さまざまなLLMとの互換性が高く、ユーザーはプロジェクトの要件に応じて技術スタックを選択できます。
さらに、LlamaIndexはオープンソースとして提供されているため、開発者が機能を追加したり、既存の機能をカスタマイズすることが可能です。
効率的な情報検索
LlamaIndexは、高度なアルゴリズムを用いて、大量のデータから迅速かつ正確に必要な情報を抽出します。これにより、ユーザーの質問に対して関連性の高い回答を素早く提供することが可能になります。
また、検索結果は、LLM(大規模言語モデル)に直接提供されます。これにより、LLMは最新かつ関連性の高い情報を基に回答を生成することができ、より正確で文脈に即した応答が可能になります。
初心者でも簡単に設計・運用できる
LlamaIndexは、直感的な設計とユーザーフレンドリーなインターフェースにより、AIやデータベース管理の経験が浅い初心者でも簡単に利用できる仕組みとなっています。
LlamaIndexのAPIはシンプルかつ分かりやすく設計されており、コード記述の負担を軽減します。また、公式ドキュメントやサンプルコードが充実しており、学習リソースとして活用することで、初心者でも効率的にAI開発に関する知識を習得できます。
さらに、一般的なプログラミング環境やツールとの互換性が高く、既存のシステムやデータベースにも統合できます。このため、新たな環境構築に時間を取られることなく、既存データを活用しながら設計や運用を進めることが可能です。
企業がLlamaIndexを活用する方法

LlamaIndexをシステム開発で活用することで、開発者や企業にメリットを提供します。以下では、LlamaIndexを活用するメリットについて解説します。
RAGを効率的に開発できる
LlamaIndexは、RAGの開発を効率化するために最適なツールです。適切なデータ処理と統合が求められるRAGの開発工程において、LlamaIndexは開発プロセスを簡素化します。
LlamaIndexは、PDFファイル、APIデータ、SQLデータベース、クラウドストレージなど、様々な形式のデータを簡単に取り込むことができます。これにより、企業は社内の分散したデータを一元管理し、RAGシステムの基盤として活用できます。
そして、LlamaIndexはVectorStoreIndexなどの高度なインデックス技術を使用して、大量のデータを迅速に整理・分類します。これにより、大量のデータセットから必要な情報を検索するプロセスが高速化され、LLMが必要な情報に即座にアクセスできる環境が構築されます。
また、初心者向けの高レベルAPIから、詳細なカスタマイズが可能な低レベルAPIまで、幅広いニーズに対応できます。開発者はデータを手軽に取り込み、LLMとの連携を迅速に構築できます。
RAGを支える技術やツールとして、LlamaIndex以外に以下が挙げられます。
| フレームワークとライブラリ | LangChain | RAGを含む様々なLLMアプリケーションの開発を支援するライブラリ |
| 基盤技術 | Embedding | テキストを数値ベクトルに変換する技術 |
| ベクトル検索 | 埋め込みベクトル間の類似性に基づく検索手法 | |
| データ前処理 | RAGチャンク | 文書を適切なサイズに分割する技術 |
| 検索最適化技術 | Hybrid Search | ベクトル検索とキーワード検索を組み合わせた手法 |
| Rerankモデル | 検索結果を再評価し、より関連性の高い順に並べ替える技術 | |
| クラウドサービス | Azure AI Search | Microsoftが提供する高度な検索サービス |
関連記事:「RAG(検索拡張生成)の活用事例は?検索システムと生成AIを導入した企業の事例を徹底解説!」
分析タスク・カスタマーサポートでのデータ検索精度の向上
LlamaIndexの強みは、独自のインデックス構造と高度なクエリ処理能力にあります。インデックス化されたデータは、単なるキーワード検索にとどまらず、文脈や意味を考慮したセマンティック検索が可能です。このため、深いニュアンスを持つ問い合わせにも対応し、適切な回答を生成できます。
また、ベクターストアと連携することで埋め込み技術を活用した検索を実現します。ベクターストアと連携した検索方法は、データ内の概念的な類似性を評価し、より関連性の高い結果を返すことが可能です。
例えば、製造業での「品質管理プロセスの最適化」という検索に対して、直接的な品質管理手法だけでなく、関連する生産効率化や在庫管理の手法も含めた総合的な情報を提供できます。
さらに、LlamaIndexの高度な検索機能により、企業は最新の市場動向や消費者行動パターンをリアルタイムで分析できます。これにより、迅速かつ的確な戦略的決定が可能になります。
検索精度の向上は、情報検索やレコメンデーション、ナレッジベースの構築など、さまざまな用途に効果的です。LlamaIndexを活用したチャットボットを使えば、製品情報や顧客データを即座に検索し、自然な対話を通じてリアルタイムで顧客の問い合わせにも対応できるでしょう。
LlamaIndexを導入することで、ユーザーは迅速に必要な情報へアクセスできるようになります。
LLM×RAGに強い会社の選定・紹介を行います
今年度RAG相談急増中!紹介実績1,000件超え!
・ご相談からご紹介まで完全無料
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
完全無料・最短1日でご紹介 LLM×RAGに強い会社選定を依頼する
LlamaIndexを活用したRAGの構築手順
LlamaIndexを用いることで、RAGシステムを効率的に構築できます。LlamaIndexを使ったRAGの構築手順は、以下の通りです。
- LlamaIndexのインストールと環境設定
- 独自データの準備と前処理
- データのインデックス化
- 検索機能の設定
- LlamaIndexとLLMの連携
- ユーザーインターフェースの構築
- デプロイと運用環境での実行
それぞれの手順について解説していきます。
LlamaIndexのインストールと環境設定
LlamaIndexを活用するには、ライブラリのインストールと環境設定が必要です。
まず、Pythonがインストールされている環境を用意します。推奨されるバージョンはPython 3.8以上で、Pythonのパッケージ管理ツールであるpipを使用すればインストールできます。
RAG開発に必要なパッケージがある場合、それらも追加でインストールします。バックエンドで使用するLLMやベクターストア(Pinecone、Weaviateなど)のライブラリを必要に応じて導入します。
次に、LlamaIndexを使うための環境設定を行います。これには、APIキーやデータベース接続情報などの設定が含まれます。デフォルトではOpenAIのモデルを使用するため。OpenAIのAPIキーが必要です。
独自データの準備と前処理
開発環境が整ったら、使用するデータを揃えます。企業に蓄積されたテキストやPDF、データベースといった形式がバラバラなデータでも収集します。
次に、データをインデックス化するための前処理を行います。特に非構造化データの場合、前処理が不可欠です。前処理には、以下のような作業が含まれます
- データ形式の統一
- 不要データの削除
- テキストのクリーンアップ
- 分割とトークン化
さらに、データにメタ情報を付与することも推奨されます。データのソースや作成日時、カテゴリなどの属性情報を追加することで、後の検索やクエリ処理を効率化することが可能です。
関連記事:「データクレンジングがどのような作業なのか、AIを用いる自動化の手順・方法、サービス選定の注意点などを紹介」
データのインデックス化
前処理が完了したデータをLlamaIndexに取り込みます。読み込まれたデータは分割され、個々のチャンクとして処理されます。チャンクサイズは、モデルが処理できるトークン数を考慮して設定する必要があります。
次に、LlamaIndexが各チャンクに対してLLMや埋め込みモデルを活用し、テキストの意味や文脈を数値ベクトルとして表現します。これらのベクトルは、後に類似性検索を行う際に活用されます。
LlamaIndexは以下のように複数のインデックスタイプを提供しています。
- VectorStoreIndex
- SummaryIndex
- KnowledgeGraphIndex
生成されたベクトルデータは、ベクターストアに保存されます。LlamaIndexはベクターストアと連携可能で、類似性検索が高速かつ正確に実行できるよう、効率的なデータ構造が維持されます。
検索機能の設定
インデックスによって数値ベクトルとして表現されたデータを基盤とし、検索機能を設定します。LlamaIndexではベクトルデータを活用して、クエリとデータ間の類似性を計算し、関連性の高い結果を取得します。
類似性計算を効果的に行うためには、使用するベクターストアの選択と設定が重要です。例えばPineconeを使用する場合、高速な類似性検索とスケーラビリティが可能となり、大規模なデータセットにも対応できます。
LlamaIndexは単純なキーワード検索から高度な文脈ベースのクエリまで対応しており、必要な情報を引き出す設定が可能です。クエリ拡張や重み付けを活用することで、検索結果の精度をさらに向上させることが期待できます。
また、検索結果の出力形式をカスタマイズすることも可能です。クエリに関連するメタデータを表示する設定を行うことで、検索結果の理解度が高まり、ユーザーエクスペリエンスが向上します。
LlamaIndexとLLMの連携
検索機能を設定したら、LlamaIndexとLLMを連携させます。これにより、LLMはLlamaIndexが構築したインデックスを活用し、外部データを効率的に検索して、文脈に基づく精度の高い応答を生成することが可能になります。
連携には、LlamaIndexと使用するLLMのAPIの統合が不可欠です。デフォルトでOpenAIのモデルを使用しますが、他のLLMモデル(例:Llama 2、Claude)も使用可能です。
OpenAIのGPTシリーズやAnthropicのClaudeなど、選択したLLMのAPIキーや接続設定をLlamaIndexに組み込むことで、データ検索と応答生成をシームレスに連携させる準備をします。
ユーザーインターフェースの構築
ユーザーインターフェース(UI)の設計の初期段階では、専門知識を持たないユーザーでも簡単に情報を探せる設計が求められます。
LlamaIndexそのものはバックエンドフレームワークであり、UIの構築は別途行う必要があります。
デプロイと運用環境での実行
LlamaIndexを活用したRAGシステムを構築した後は、RAGシステムをホストする環境を選定します。クラウドプラットフォーム(AWS、Google Cloud、Azureなど)を利用する場合は、スケーラビリティや可用性を考慮して構成を設計します。
RAGの運用中は、ユーザーからのフィードバックをもとにシステムを改善するサイクルを維持しましょう。LlamaIndexの検索性能やLLMの応答精度が、実際の使用状況に応じて最適化されるように設定を微調整します。
LlamaIndexについてよくある質問まとめ
- LlamaIndexとは何ですか?
LlamaIndexは、大規模言語モデル(LLM)の開発に利用されるオープンソースのPythonライブラリです。このライブラリは、データ管理と活用を効率化する手法を提供し、LLMの自然言語処理能力を特定のデータセットに効果的に応用することを可能にします。
- LlamaIndexとLangChainの違いは何ですか?
LlamaIndexは、高速かつ高精度な性能を持ち、ドキュメント検索や大規模言語モデルの強化といったタスクに最適です。一方で、LangChainは柔軟性と多機能性が特徴で、拡張性の高いツールとして活用されています。
まとめ
LlamaIndexは、LLMと独自データを連携させるための強力なツールとして、RAGシステム構築に優れています。LlamaIndexが持つ拡張性や幅広いデータソースへの適用力は、企業や開発者が直面する課題を解決し、効率的な開発を可能にするでしょう。
LlamaIndexを活用することで、膨大なデータから有用な情報を引き出し、LLMの性能を最大化する高度なシステムを構築することが可能です。ナレッジ検索やレコメンデーションエンジン、意思決定支援システムなど、多様なユースケースに適応できる汎用性を持っています。
LlamaIndexを取り入れる際には、プロジェクトの目的やリソースに応じた設計を行い、継続的なメンテナンスと改善が必要です。最適な実装には、データの特性や利用目的に応じた適切な設計が求められます。
特に大規模なシステム構築や本番環境での運用を検討される場合は、RAGやベクトルデータベースに精通した専門家への相談をお勧めします。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

