
SAM Audio とは?特徴、機能、性能、ライセンス・料金、利用方法まで徹底解説!
最終更新日:2026年01月14日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- Metaが2025年12月に音声分離特化の統合型AIモデル「SAM Audio」を発表
- テキスト・視覚・時間指定の3種類のプロンプトで目的の音を高精度分離
- 環境音・音楽・発話を単一モデルで処理、研究用途向けに無償公開
- 既存モデルと比較し楽器で90%超、発話で89%の勝率を記録
- 補聴器やクリエイティブ制作など幅広い分野での活用に期待
SAM Audioは、Metaが発表した音声分離に特化した統合型マルチモーダルAIモデルです。テキスト、視覚、時間範囲といった直感的なプロンプトを用いることで、複雑に混ざり合った音声や映像付き音源から目的の音だけを高精度に分離できます。
また、従来の音声認識AIツールとは異なり、人が自然に音を認識・指定する感覚に近い操作性を重視して設計されています。
音声処理を「エンジニアやプロだけの特権」から「誰もが直感的に扱えるツール」へと変えるSAM Audioが、貴社の新規事業や業務改善にどのようなインサイトをもたらすのか、技術的背景から具体的な活用フローまでを解説します。
音声認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 音声認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
音声認識に強いAI開発会社をご自分で選びたい方はこちらで特集していますので併せてご覧ください。
目次
SAM Audioとは?
SAM Audio(Segment Anything in Audio)は、Metaが2025年12月に公開した音声分離のための統合型マルチモーダルAIモデルです。
画像や動画における物体検出で知られるSegment Anything Model(SAM)の思想を音声認識領域に拡張したもので、特定の音を「言葉」や「映像内の物体」で指定し、自由自在に分離・抽出・除去することを可能にします。
音声・音楽・発話といった異なる音の種類を単一のモデルで扱える点が特徴です。
開発背景
| 項目 | 従来の音声分離 | SAM Audio |
|---|---|---|
| 分離対象 | 特定の既知カテゴリのみ(歌声、楽器等) | あらゆる音(犬の鳴き声、足音、特定の人の声、サイレン等) |
| 入力方式 | 固定された設定 |
|
| 柔軟性 | 低い(新しい音には再学習が必要) | 高い(プロンプト一つで未学習の音にも対応) |
開発背景には、音声編集や音声理解が用途別ツールに分断されてきた課題があり、誰でも直感的に音を切り分けられる基盤を提供することが目的とされています。
これまでの音声分離技術(SpleeterやDemucsなど)は、「ボーカル」「ドラム」「ベース」といった、あらかじめ定義されたカテゴリしか分離できませんでした。しかし、SAM AudioはUniversal Audio Source Separation(汎用音源分離)を実現します。
音声認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 音声認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
SAM Audioの特徴
SAM Audioは、音声分離を実現するために、以下の特徴的な設計を採用しています。
マルチモーダルプロンプトの併用
SAM Audioでは、テキスト・ビジュアル・スパンの各プロンプトを単独でも併用でも使用可能です。音の内容、映像上の位置、時間範囲を同時に条件として指定することで、より精度の高い音声分離を実行できます。
ユーザーは「犬の鳴き声」といったテキストによる指定、動画上の音源を直接クリックする視覚的な指定、特定の時間区間を示すスパン指定を単独または組み合わせて使用できます。
このように、複数の情報を組み合わせて分離条件を与えられる点が、SAM Audioの大きな特徴です。
汎用的な音声分離への対応
SAM Audioは、一般音(環境音など)・音楽・発話といった異なる音声カテゴリを単一の枠組みで扱える点が特徴です。
動画内で「この人」や「この楽器」をクリックするだけで、その対象が発している音だけを抽出します。これはMetaの「Perception Encoder Audiovisual(PE-AV)」という新エンジンにより、映像と音声の時間軸・空間軸を極めて精密に同期させているためです。
これにより、複雑に音が混ざり合った環境でも、目的の音を直感的に指定することが可能です。
特定用途に特化したモデルではなく、現実世界における多様な音の混在を前提とした設計となっており、幅広いシナリオで一貫した操作体験を提供します。
生成型音声分離アーキテクチャ
SAM Audioは、テキスト・ビジュアル・時間的プロンプトを用いて、混合音声からターゲット音と残差音の両方を同時に抽出する生成分離モデルです。
中核にはフローマッチング型Diffusion Transformerが採用されており、DAC-VAEの潜在空間上で処理を行うことで、ターゲット音と残差音を高品質に同時生成できる設計となっています。
この生成的アプローチにより、複雑な音の重なりを含む音源に対しても、安定した音声分離が可能です。
Perception Encoder Audiovisual(PE-AV)との連携
SAM Audioの中核には、Perception Encoder Audiovisual(PE-AV)が組み込まれています。
これは、映像フレームと音声を時間的に整合させて理解するためのエンコーダであり、視覚情報に基づく音源の特定や、画面外音源の文脈推定を可能にしています。
参考:Introducing Meta Segment Anything Model Audio (SAM Audio)
SAM Audioの機能
SAM Audioには、音声分離を柔軟かつ直感的に行うための複数の機能が用意されており、用途や音源の特性に応じて使い分けることができます。
テキストプロンプトによる音声分離
SAM Audioでは、分離したい音をテキストで指定する操作が可能です。
ユーザーは対象となる音を自然言語で入力することで、音声または映像付き音源の中から、その指示に対応する音を分離対象として指定できます。「カラスの鳴き声だけ消して」「遠くで鳴っている救急車の音を抽出して」といった自然言語による指示が可能です。
これは、非エンジニアの現場スタッフでも高度な音声編集が可能になることを意味します。
テキスト入力は、環境音・音楽・発話といった音の種類ごとに利用でき、入力内容に応じた分離処理が自動で行われます。
ビジュアルプロンプトによる音声分離
映像を含む音源では、動画上の人物や物体をクリックすることで音声分離を指示できます。ユーザーが画面上で指定した位置に対応する音が分離対象として扱われ、映像と同期した音声処理が実行されます。
この機能により、映像内の特定の発音源や発話者を視覚的に指定したうえで音声分離を行えます。
スパンプロンプトによる時間指定分離
SAM Audioは、タイムライン上の特定区間を指定して音声分離を行うスパンプロンプトに対応しています。ユーザーは音声や動画の中で対象音が含まれる時間範囲を指定し、その区間をまとめて分離対象として処理できます。
これにより、同一の音が継続して発生する区間を効率よく分離することが可能です。
音声認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 音声認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
SAM Audioの性能
SAM Audioは、音声分離性能とマルチモーダル理解の両面で高い評価を示しています。ここでは、公式に公開されている評価結果をもとに、その性能を整理します。
音声分離性能(Net Win Rateによる比較)
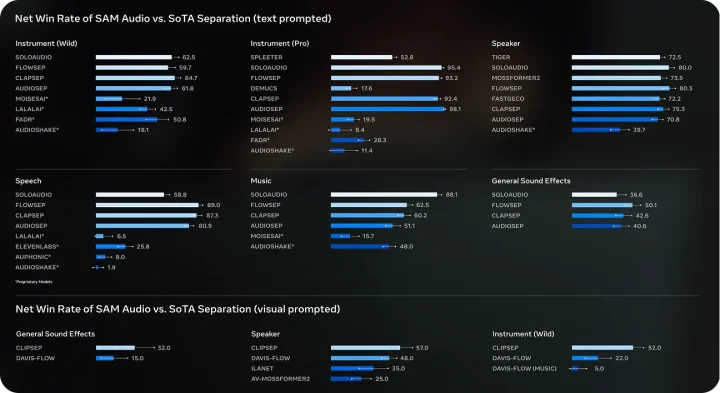
上記の画像は、SAM Audioが既存の最先端(SoTA)音声分離モデルと比較して、人間評価に基づくNet Win Rate(勝率)でどの程度優位かを示したものです。
テキストプロンプトでは多くのカテゴリで、既存モデルに対して以下の勝率を示しており、幅広い音種に対応できていることが分かります。
- 楽器:90%超(最大約98%)
- 発話:最大約89%
- 音楽:約88%
- 一般音:約50%前後
ビジュアルプロンプトでも話者分離で最大約57%、楽器分離で約52%と視覚情報を用いた条件下でも安定した性能が確認されています。
基盤モデルPE-AVの理解性能
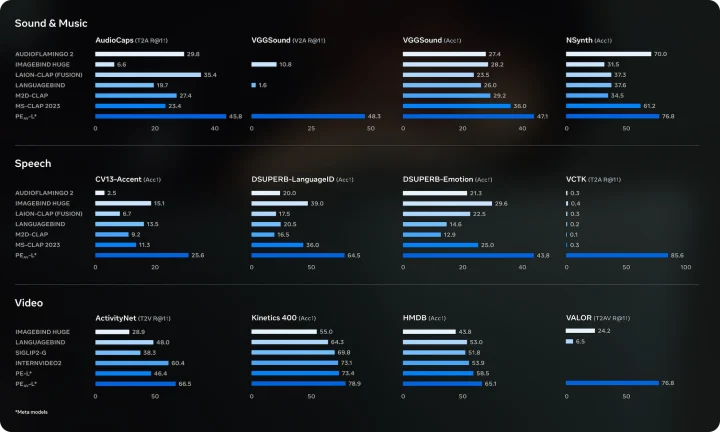
上記画像は、SAM Audioの基盤であるPerception Encoder Audiovisual(PE-AV)が、音・発話・動画の各ベンチマークで示した性能をまとめたものです。
音・音楽、発話、動画の各分野で高いスコアを安定して記録しており、音声と映像を統合して理解できる強力な基盤モデルであることが分かります。
評価データセットの構成(SAM Audio-Bench)
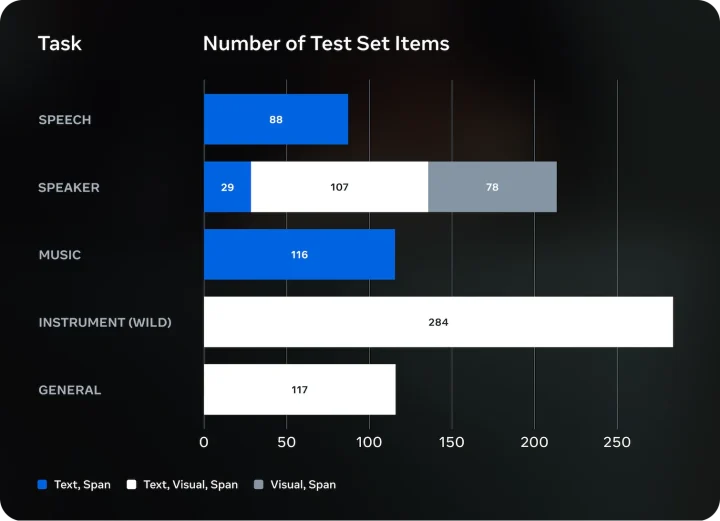
SAM Audioの評価には、実運用に近い多様な音声タスクを含むベンチマーク「SAM Audio-Bench」が用いられています。評価構成のポイントは以下のとおりです。
- 発話・話者・音楽・楽器・一般音といった幅広い音種を網羅
- 楽器(Instrument・Wild)が最多で、複雑な音の混在環境を重視
- テキスト・ビジュアル・スパンを組み合わせたマルチモーダル条件で評価
このことから、SAM Audio-Benchは単一条件に偏らない実践的な評価設計となっており、SAM Audioの汎用性と安定した性能を裏付けるベンチマークであることが分かります。
SAM Audioのライセンス・料金体系
SAM Audioは、Metaが研究用途向けに無償で公開しているモデルです。Segment Anything Playgroundで利用する場合でも、モデルをダウンロードしてローカル環境で実行する場合でも料金は発生しません。
なお、商用利用に関する条件やライセンスの詳細については、公式ドキュメントをご確認ください。
参考:公式発表
SAM Audioの使い方
SAM Audioでは、モデルをダウンロードして利用する方法とPlayground上で操作する方法の2通りが用意されています。
モデルをダウンロードして利用する
SAM Audioは、Playground上での利用に加えて、モデルを直接ダウンロードして利用することも可能です。研究用途やローカル環境での検証を行いたい場合には、この方法が適しています。
- GitHubリポジトリへアクセスする

使い方の一つとして、画面に表示されている「Download the model」をクリックすると、GitHubの公開リポジトリへ遷移します。 - モデルとコードをローカル環境で利用する
SAM Audioのモデルや関連コードはGitHub上で公開されており、内容を確認したうえでローカル環境にダウンロードして利用することが可能です。
Playgroundで利用する方法
SAM Audioは、Playground上で直感的に操作できる設計となっており、音声分離から編集・保存までをスムーズに行えます。ここでは、基本的な使い方の流れを紹介します。
- SAM Audioを起動する
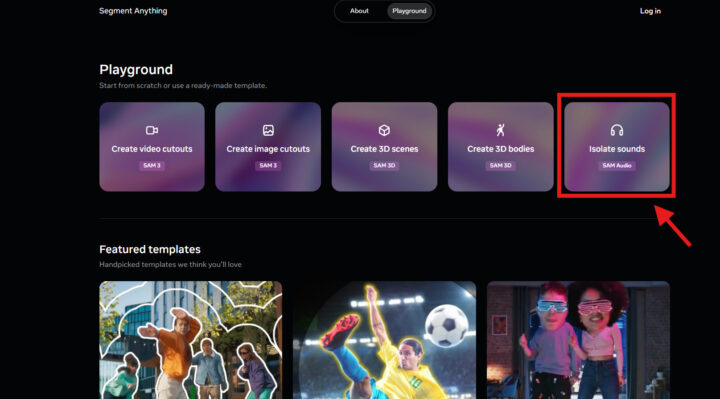
SAM Audioは、Segment AnythingのPlayground上で提供されています。 - 利用する際は、Playground内のメニューから「SAM Audio」を選択します。
- 音声・動画素材を選択する
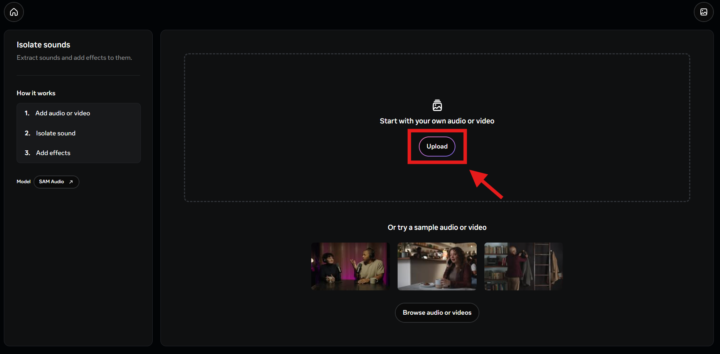
ユーザーは、あらかじめ用意された音声・動画素材を選択するか、自身のデータをアップロードして使用できます。その後、テキスト入力、映像クリック、時間範囲指定といった操作を通じて、音声分離を体験できます。 - テキストで分離したい音を指定する

画面上部の赤い枠で示された入力欄に、抽出したい音をテキストで入力します。たとえば「女性」のように、日本語での指定にも対応しています。 - 入力後、左下にある「Isolate sound」をクリックすると、指定した音だけを抽出・分離する処理が開始されます。
- 分離後の音声を調整・書き出す
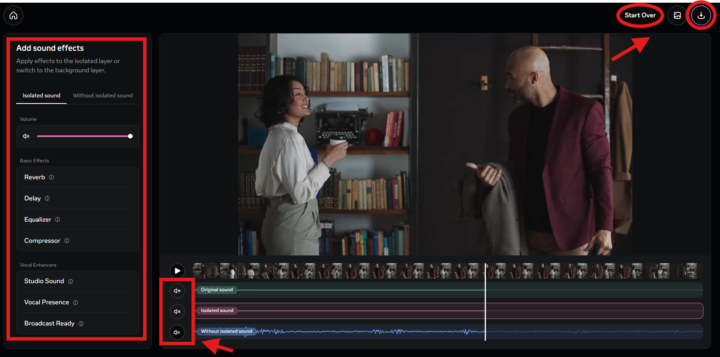
上記画面は、SAM Audioで音声編集を仕上げるための最終調整画面です。- 左側のパネル:分離した音(Isolated sound)と背景音(Without isolated sound)を切り替えながら編集
音量調整に加え、リバーブやイコライザーなどの基本エフェクトや、音声を聞き取りやすくする補正機能を適用できます。 - 画面下部のタイムライン:レイヤーごとに再生して仕上がりを確認
- 右上の「Start Over」では編集を最初からやり直すことができ、ダウンロードアイコンから編集後のデータを書き出しが可能
- 左側のパネル:分離した音(Isolated sound)と背景音(Without isolated sound)を切り替えながら編集
このように、SAM Audioでは音の分離から調整、保存までを一画面で完結できる点が大きな特徴です。
SAM Audioのテキストプロンプトによる音声分離をAI Market編集部で実際に使ってみました
上記の動画は、PlaygroundにおけるSAM Audioの一連の操作を実際に試した様子を示しています。テキスト欄に「女性」と入力して送信するだけで、その指示に基づいて音声が分離されました。
周囲の雑音は抑えられ、目的とする音声が明確に判別された状態で抽出されており、テキストで指定するだけの簡単な操作で、狙った声を正確に分離できることが確認できます。
音声認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 音声認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
SAM Audioに関するよくある質問まとめ
- SAM Audioはどのようなプロンプトに対応していますか?
SAM Audioは、テキスト、視覚、時間範囲という3種類のプロンプトに対応しています。テキストでは「犬の鳴き声」のように自然言語で音を指定でき、視覚では動画上の人物や物体をクリックして音源を指定できます。また、タイムライン上の特定区間を指定するスパンプロンプトにも対応しており、これらを単独または組み合わせて使用することで、複雑な音源から目的の音を高精度に分離できます。
- SAM Audioは無料で使えますか?
はい、SAM AudioはMetaが研究用途向けに無償で公開しているモデルです。Segment Anything Playgroundで利用する場合でも、モデルをダウンロードしてローカル環境で実行する場合でも、料金は発生しません。ただし、商用利用に関する条件やライセンスの詳細については、公式ドキュメントで確認する必要があります。
- 自社の既存アプリや現場の端末にSAM Audioを組み込むことは可能ですか?
技術的には可能ですが、商用利用のライセンス確認やハードウェアの計算リソース(GPU)との整合性確認が必要です。 AI Marketでは、こうした最新モデルの実装経験を持つ開発会社の中から、貴社のインフラ環境や予算規模に最適なパートナーを厳選してご紹介いたします。まずは「自社の環境で動くか」という初期診断からご相談いただけます。
- 特殊な工場の機械音や、特定の個人の声など、学習データに少なそうな音でも分離できますか?
SAM Audioは高い「ゼロショット性能(未学習への対応力)」を持っていますが、極めて特殊な環境では精度が落ちる場合もあります。 実務で運用可能か判断するためのPoC(概念実証)の設計にお悩みであれば、AI Marketのコンシェルジュが、音声解析に強い開発ベンダーをマッチングし、最適な検証プランの策定をサポートします。
まとめ
SAM Audioは、音声分離を誰もが直感的に扱えるようにすることを目指した、統合型マルチモーダルAIモデルです。
テキスト・視覚・時間指定を組み合わせた柔軟な操作性と、最先端の生成型アーキテクチャにより、音声、音楽、発話といった多様な音を高精度に切り分けられる点が特徴です。
今後、クリエイティブ制作、研究、アクセシビリティ支援など、幅広い分野での活用が期待されています。
自社の課題に対してSAM Audioが最適な解であるか、あるいは他の音声AIとの組み合わせが有効か、より深い技術選定や費用対効果の検証が必要な場合は、専門家の知見を借りるのが最短ルートとなります。
音声活用の可能性を具体的な事業計画へと落とし込むために、まずは技術検証の第一歩を踏み出してみてはいかがでしょうか。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

