
Qwen3-LiveTranslateとは?特徴、性能、料金プラン、利用方法、活用事例まで徹底解説!
最終更新日:2025年11月25日
記事監修者:森下 佳宏|BizTech株式会社 代表取締役

- Qwen3-LiveTranslateは18言語対応の多言語リアルタイム通訳モデルで、音声と映像を統合解析し文脈精度を向上
- 入力から出力まで3秒以内の低遅延を実現、意味単位予測技術で非リアルタイム翻訳の94%精度を維持
- FLEURSベンチマークで競合モデルを上回る翻訳精度を記録、ビジネス会議や放送での活用を想定
Qwen3-LiveTranslateは音声と映像を同時に解析できるマルチモーダル翻訳AIです。わずか3秒という低遅延で高精度なリアルタイム通訳を実現します。
オンライン・オフライン双方の通訳をサポートし、国際会議、教育、メディア、観光など多様なシーンでの即時翻訳を可能にします。
本記事では、Qwen3-LiveTranslateの特徴、性能、料金プラン、利用方法、 活用事例までを徹底的に解説します。
音声認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 音声認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
目次
Qwen3-LiveTranslateとは?
🚀 Introducing Qwen3-LiveTranslate-Flash — Real‑Time Multimodal Interpretation — See It, Hear It, Speak It!
🌐 Wide language coverage — Understands 18 languages & 6 dialects, speaks 10 languages.
👁️ Vision‑Enhanced Comprehension — Reads lips, gestures, on‑screen text and… pic.twitter.com/KkrOUqhehX— Qwen (@Alibaba_Qwen) September 23, 2025
Qwen3-LiveTranslateは、、AlibabaのQwenチームが開発したリアルタイムの音声・映像通訳を目的とした多言語翻訳AIモデルです。
AirPods Pro + iOSのライブ翻訳機能を含め、従来の翻訳AI(ASR + LLM + TTS)の多くは、「音声波形」のみを頼りにしていました。しかし、Qwen3-LiveTranslateは、 音声だけでなく、カメラ映像から「唇の動き(読唇術)」や「ジェスチャー」を認識し、翻訳精度を向上させます。
例えば、製造業の工場ライン、建設現場など、騒音が激しい環境では既存の音声翻訳機は使い物になりません。Qwen3-LiveTranslateであれば、作業員の「口元」や「身振り(危険を知らせるジェスチャーなど)」を認識補助に使えるため、高ノイズ環境下での指示伝達や安全確認の効率が向上します。
Qwen3-Omniを基盤に構築されており、数百万時間におよぶマルチモーダルデータで学習されています。日本語を含む18言語に対応し、音声・映像・テキストを横断して自然な会話を支援します。
音声認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 音声認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
Qwen3-LiveTranslateの特徴
Qwen3-LiveTranslateは、言語の網羅性、映像解析による理解精度、処理速度、音声表現力のすべてにおいて高い完成度を誇ります。その主な特徴は以下のとおりです。
多言語・方言の広範な対応
Qwen3-LiveTranslateは、主要18言語と複数の方言に対応するの同時通訳モデルです。以下の表は、Qwen3-LiveTranslateで対応する言語と出力形式を示したものです。
| 言語コード | 言語名 | 出力形式 |
|---|---|---|
| en | 英語 | 音声+テキスト |
| zh | 中国語 | 音声+テキスト |
| ru | ロシア語 | 音声+テキスト |
| fr | フランス語 | 音声+テキスト |
| de | ドイツ語 | 音声+テキスト |
| pt | ポルトガル語 | 音声+テキスト |
| es | スペイン語 | 音声+テキスト |
| it | イタリア語 | 音声+テキスト |
| ko | 韓国語 | 音声+テキスト |
| ja | 日本語 | 音声+テキスト |
| yue | 広東語 | 音声+テキスト |
| id | インドネシア語 | テキスト |
| vi | ベトナム語 | テキスト |
| th | タイ語 | テキスト |
| ar | アラビア語 | テキスト |
| hi | ヒンディー語 | テキスト |
| el | ギリシャ語 | テキスト |
| tr | トルコ語 | テキスト |
上記以外にも、以下の中国国内の主要方言にも対応しており、発音・アクセント・リズムなど地域特有の特徴を正確に識別します。
- 呉語(上海語)
- 四川語
- 天津方言
こうした柔軟な音声認識能力により、単なる文脈翻訳ではなく、話者の文化的背景やニュアンスを反映した自然な通訳が可能となっています。
視覚情報を活用した理解
Qwen3-LiveTranslateは音声のみならず映像情報をも統合的に解析します。唇の動き、表情・ジェスチャー・画面上の文字・実世界の物体などを検出し、音声の意味を補完することで精度を高めます。
これにより、騒音下や不明瞭な発音環境でも正確な意味理解を実現します。
また、同音異義語や専門用語など曖昧な語を文脈から正しく解釈する能力を持ちます。上記の動画では、「mask」という単語が医療用マスク・フェイスパック・仮面・人名「Musk」を指す場合でも、映像情報から適切な翻訳を選択します。
視覚文脈を組み合わせることで、音声のみでは不可能だった意味の解像度を大幅に向上させています。
3秒の低遅延で同時通訳
Qwen3-LiveTranslateは、軽量なMixture-of-Experts(専門家混合)アーキテクチャと動的サンプリング手法を組み合わせ、入力から出力までの遅延をわずか3秒以内に抑えます。
これは従来の音声翻訳システムと比較しても極めて短く、ライブ会議や講演、国際放送などでも違和感のないテンポで対話が続けられます。
翻訳は単語単位ではなく、意味単位ごとに逐次処理されるため、文脈を失わずに即時応答が可能です。結果として、「聞く・話す」をリアルタイムで循環させる自然な通訳体験を提供します。
自然な音声生成
Qwen3-LiveTranslateは数百万時間におよぶ大規模音声データセットで訓練されており、翻訳結果を自然で感情豊かな音声として出力します。単なる機械音声ではなく、発話者のトーン・抑揚・テンポ・感情表現を文脈に応じて再現します。
音声ボイスの一部を以下に示します。声質の特徴と対応言語が異なります。
| スピーカー名 | 特徴 | 対応言語・方言 |
|---|---|---|
| Cherry | 明るく自然な女性の声 | 中国語、英語、フランス語、ドイツ語、日本語など |
| Nofish | レトロ音を発音できないデザイナー風の声 | 中国語、英語、フランス語、ドイツ語、日本語など |
| Jada | 情熱的な上海方言の女性 | 中国語(上海方言) |
| Dylan | 北京の胡同で育った若い男性 | 中国語(北京方言) |
| Sunny | 心を和ませる四川出身の女性 | 中国語(四川方言) |
| Peter | 天津スタイルの話し方をする男性 | 中国語(天津方言) |
| Kiki | 香港出身の恋人のような声 | 広東語 |
| Eric | 自由な雰囲気を持つ成都の男性 | 中国語(四川方言) |
これにより、通訳結果は単調ではなく、まるで人間の通訳者がその場で話しているような臨場感を持ちます。特に教育・報道・ビジネスプレゼンなど、聞き手の理解と集中を促す自然な音声表現が求められる場面で高い効果を発揮します。
参考:Qwen3‑LiveTranslate: Real‑Time Multimodal Interpretation
Qwen3-LiveTranslateの性能
以下に、Qwen3-LiveTranslate-Flashが示す翻訳精度やベンチマーク結果を整理し、その性能をわかりやすくまとめています。
他モデルとの比較で安定した高精度翻訳を実現
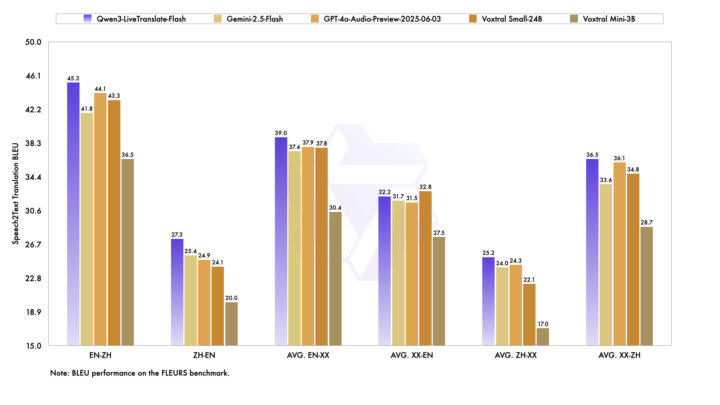
Qwen3-LiveTranslate-Flashは、FLEURSベンチマークにおける音声翻訳精度(BLEUスコア)で、Gemini-2.5-FlashやGPT-4o-Audio-Previewなどの他モデルを上回る結果を示しました。
特に英語→中国語で45.3、他言語→中国語で36.5を記録し、いずれも最高値を達成しています。英語・中国語間だけでなく、多言語ペアでも安定した精度を維持しており、リアルタイム翻訳においても自然で一貫した品質を実現しています。
多領域で一貫した高精度を発揮
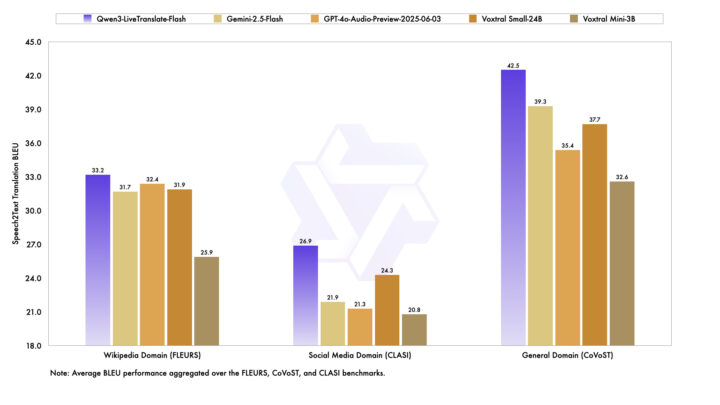
上記のグラフは、Qwen3-LiveTranslate-Flashと他モデル(Gemini-2.5-Flash、GPT-4o-Audio-Preview、Voxtral Small-24B、Voxtral Mini-3B)の翻訳精度を、Wikipedia(FLEURS)・SNS(CLASI)・一般会話(CoVoST)という3つの領域で比較したものです。
指標は翻訳精度を示すBLEUスコアです。Qwen3-LiveTranslate-Flashはすべての領域で他モデルを上回り、特に一般会話領域(CoVoST)で42.5を記録し、最も自然で正確な翻訳を実現しました。
また、SNSなどノイズの多い環境を想定したソーシャルメディア領域(CLASI)でも26.9を記録し、Gemini-2.5-Flash(21.9)やGPT-4o-Audio-Preview(24.3)を上回る結果を達成しています。
ロスレス翻訳技術
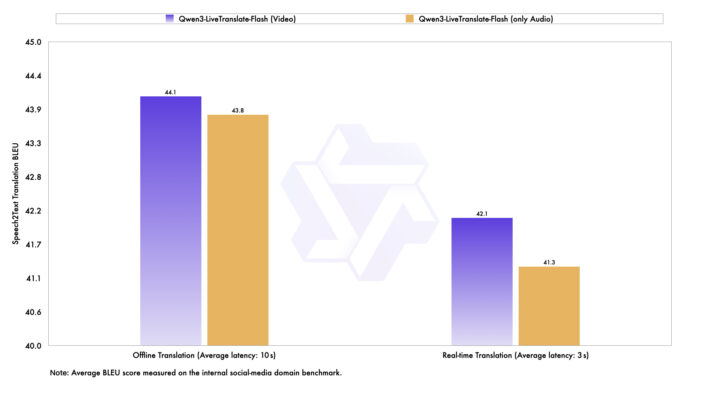
Qwen3-LiveTranslateの中核をなすのが、意味単位予測(semantic unit prediction)技術です。言語間で語順が大きく異なる場合に発生する構文のずれや意味の欠落を自動的に補正し、リアルタイム翻訳でもオフライン翻訳に匹敵する精度を実現します。
この技術により、英語・中国語・日本語のような文法構造が異なる言語間でも、情報の抜け落ちを最小限に抑えます。上記のグラフから、同時通訳でありながら非リアルタイム翻訳の約94%の正確度を維持しています。
音声認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 音声認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
Qwen3-LiveTranslate(API)の使い方
Qwen3-LiveTranslateは、以下の手順で利用できます。
- 接続設定
- 認証
- セッション設定
- 音声・画像データの送信
- 出力結果の取得
1. 接続設定
WebSocketプロトコルを使用して接続します。
- 中国本土版:wss://dashscope.aliyuncs.com/api-ws/v1/realtime
- 国際版:wss://dashscope-intl.aliyuncs.com/api-ws/v1/realtime
接続URLの末尾に、利用するモデル名を指定します。
例:?model=qwen3-livetranslate-flash-realtime
2. 認証
リクエストヘッダーにAPIキーを設定します。
Authorization: Bearer DASHSCOPE_API_KEY
(DASHSCOPE_API_KEYはAlibaba Cloud Model Studioで発行)
3. 初期ハンドシェイク(タスク設定)
接続確立後、最初のフレームでモデルとモード(翻訳・通訳)を指定します。ここでQwen3特有の「視覚情報利用(Visual Context)」を有効化します。
{
"header": {
"action": "run-task",
"task_id": "uuid-generated-by-client"
},
"payload": {
"model": "qwen3-livetranslate-flash",
"parameters": {
"mode": "simultaneous_interpretation", // 同時通訳モード
"input": {
"modalities": ["audio", "video"] // 映像入力を許可
},
"output": {
"audio": { "voice": "cherry" } // 任意の音声モデル
}
}
}
}4. 音声・画像データの送信
バイナリフレーム、またはJSON形式でストリームデータを送信します。Qwen3-LiveTranslateでは、音声パケットに同期して映像のキーフレームを送ることで、口の動き(リップシンク)による補正がかかります。
- アクション: continue-task
- データ: 音声PCMデータおよび映像フレーム(Base64等)
5. 出力結果の取得
サーバーからは非同期イベントとして翻訳結果が返されます。
- event: task-started: 処理開始
- event: result-generated: 翻訳テキストと音声データ(逐次)
- event: task-finished: セッション終了
参考:https://www.alibabacloud.com/help/en/model-studio/qwen3-livetranslate-flash-realtime
Qwen3-LiveTranslateの料金
Qwen3-LiveTranslateの利用に関する料金情報を、モデル仕様と従量課金に分けてわかりやすく整理しました。
無料枠
以下の表は、Qwen3-LiveTranslateのモデル仕様と無料枠のみを整理したものです。無料枠は100万トークン(90日間)で、Model Studioを有効化すると自動で付与されます。
| 項目 | qwen3-livetranslate-flash-realtime (Stable) | qwen3-livetranslate-flash-realtime-2025-09-22 (Snapshot) |
|---|---|---|
| バージョン | Stable(最新安定版) | Snapshot(固定版) |
| コンテキストウィンドウ(トークン) | 53,248 | 53,248 |
| 最大入力 | 49,152 | 49,152 |
| 最大出力 | 4,096 | 4,096 |
従量課金(無料枠超過後に適用)
以下の表は、無料枠を使い切った後に適用される入力・出力別の従量課金をまとめたものです。
OpenAIのRealtime API(GPT-4o Audio)の単価($200 / 100万トークン)を意識した、かなり攻撃的な価格設定になっています。
音声・画像入力、テキスト・音声出力でそれぞれ課金が発生します。
| 区分 | タイプ | 価格(USD/ 100万トークン) | 説明 |
|---|---|---|---|
| 入力 | 音声(Audio) | $10 | リアルタイム音声入力を処理するときに発生する費用 |
| 画像(Image) | $1.3 | 映像フレーム解析(唇の動き・画面文字検出など)にかかる費用 | |
| 出力 | テキスト(Text) | $10 | 翻訳結果のテキスト生成にかかる費用 |
| 音声(Audio) | $38 | 翻訳結果を音声として生成・出力する際の費用 |
特に注目すべきは、「映像(視覚情報)入力」の安さと、「音声出力」が競合比で大幅に抑えられている点です。画像入力が安価なため、カメラ映像を「毎秒1フレーム」程度の間引きで送り続け、口の動き(リップシンク)による精度向上を狙ってもコスト増は軽微です。
【試算例】
1時間のWeb会議で同時通訳(音声→音声)を使用した場合、以下の試算になります。
Qwenのトークナイザーは、概ね 1秒 ≒ 15〜20トークン 程度で処理されます(言語や沈黙により変動)。つまり、100万トークン ≒ 約14〜18時間の通話 に相当します。
- 入力(音声): 60分 × $10/1M tokensレート 換算 ≒ 約 $0.7 (約100円)
- 出力(音声): 60分 × $38/1M tokensレート 換算 ≒ 約 $2.7 (約400円)
1時間あたり 約500円 程度で、AIによる完全マルチモーダル同時通訳環境が動く計算です。
映像フレームを頻繁に送ると、ここに画像入力コストが上乗せされます(フレームレート設定に依存)。
料金は、随時変更の可能性があるので、Qwen3‑LiveTranslateの公式サイトでご確認ください。
音声認識に強いAI会社の選定・紹介を行います 今年度AI相談急増中!紹介実績1,000件超え! ・ご相談からご紹介まで完全無料 完全無料・最短1日でご紹介 音声認識に強いAI会社選定を依頼する
・貴社に最適な会社に手間なく出会える
・AIのプロが貴社の代わりに数社選定
・お客様満足度96.8%超
Qwen3-LiveTranslateの活用事例
Qwen3-LiveTranslateが実際の利用シーンでどのように役立つのかを、具体的な例を用いてわかりやすく紹介します。
音声から音声への同時翻訳
上記の動画は、ニュース番組風のタイ語の音声をリアルタイムで中国語へ翻訳しています。話者が名乗る「Ploy iMod」のような低頻度の固有名詞も、映像から得られる口元の動きや画面情報を併用することで正確に認識します。
音声だけの翻訳では「Ploy Aimod」と誤る場面でも、視覚情報を組み合わせることで適切に補正され、自然な中国語音声として出力されます。
Qwen3-LiveTranslateに関するよくある質問まとめ
- Qwen3-LiveTranslateはどのような場面で活用できるのか?
国際会議やビジネスプレゼンテーション、放送での同時通訳、多言語カスタマーサポート、教育現場での言語学習支援などでの活用が想定される。
特に音声と映像を統合解析する特性から、オンライン会議やライブ配信など視覚情報が利用できる環境での精度向上が期待できる。
3秒の低遅延により自然な対話フローを維持できるため、リアルタイム性が重視される場面に適している。
- 他の音声翻訳モデルと比較した場合の主な優位性は何か?
視覚情報を統合した文脈理解により、同音異義語や固有名詞の誤訳を防ぐ点が主な優位性だ。
FLEURSベンチマークではGemini-2.5-FlashやGPT-4o-Audio-Previewを上回る翻訳精度を記録し、特にノイズの多い環境での性能が高い。
また18言語と中国語の複数方言に対応し、意味単位予測技術により非リアルタイム翻訳の94%精度を維持しながら3秒の低遅延を実現している点も差別化要素となる。
- 料金体系はどのようになっていますか?
100万トークン単位の従量課金制です。
- 入力:音声 $10、画像 $1.3
- 出力:音声 $38、テキスト $10
OpenAIの競合サービスと比較して音声出力コストなどが大幅に抑えられており、映像入力を併用してもコストパフォーマンスが高い設計です。初期の無料枠も用意されています。
まとめ
Qwen3-LiveTranslateは、音声・映像を同時に解析し、3秒の低遅延でリアルタイム翻訳を行う革新的な通訳モデルです。従来の音声翻訳を超えて、視覚情報を統合することで精度と自然さを両立し、多言語かつ方言にも対応します。
しかし、自社の既存システムやセキュリティ要件に合わせ、最適なAPI構成(映像フレームレートの調整やネットワーク設計)を組むには専門的な知見が不可欠です。最新のマルチモーダルAI導入におけるフィジビリティスタディ(実現可能性調査)や開発パートナーの選定にお悩みの際は、ぜひAI Marketの専門コンサルタントまでご相談ください。

AI Market 運営、BizTech株式会社 代表取締役|2021年にサービス提供を開始したAI Marketのコンサルタントとしても、お客様に寄り添いながら、現場のお客様の課題ヒアリングや企業のご紹介を5年以上実施しています。これまでにLLM・RAGを始め、画像認識、データ分析等、1,000件を超える様々なAI導入相談に対応し、参加累計5,000人を超えるAIイベントを主催。AIシステム開発PM歴8年以上。AI Marketの記事では、AIに関する情報をわかりやすくお伝えしています。(JDLA GENERAL 資格保有)
▶ 監修者の実績・経歴を詳しく見る
AI Market 公式𝕏:@AIMarket_jp
Youtubeチャンネル:@aimarket_channel
TikTok:@aimarket_jp
運営会社:BizTech株式会社
掲載記事に関するご意見・ご相談はこちら:ai-market-contents@biz-t.jp

